1.1. Введение
1.2.Основные понятия
1.3.Сценарии
1.3.1.Однократное или периодическое преобразование содержимого БД в статические документы
1.3.2.Динамическое создание гипертекстовых документов на основе содержимого БД
1.3.3.Создание информационного хранилища на основе высокопроизводительной СУБД с языком запросов SQL. Периодическая загрузка данных в хранилище из основных СУБД
1.4.План отчета
1.5.Обзор технологий
1.5.1.WWW - сервер NCSA HTTPD
1.5.2.SQL - сервер фирмы Oracle
1.5.3. Библиотеки и функции на языке C
1.5.4. Язык программирования Perl
1.5.5. Пакет Web - Oracle - Web
1.5.6. Пакет Cold Fusion фирмы Allaire Corp
1.6. Оценка трудоемкости обеспечения WWW доступа
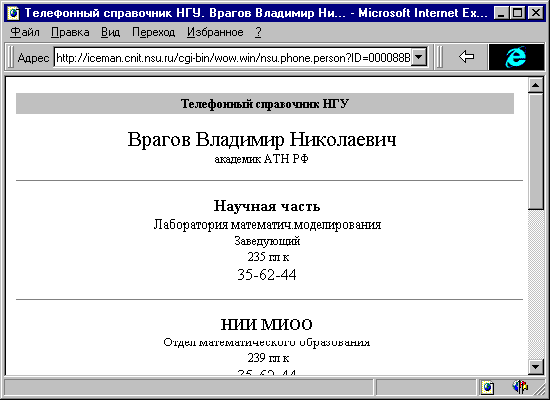
Многие организации используют электронные базы данных (БД) для поддержки своих рабочих процессов. Часто это системы на одного - двух пользователей, выполненные с использованием dbf - ориентированных средств разработки: Clipper, Dbase, FoxPro, Paradox, Access. Обычно используется ряд таких баз, независимых друг от друга. Если информация, хранимая в таких БД, представляет интерес не только для непосредственных пользователей, то для ее дальнейшего распространения используются бумажные отчеты и справки, созданные базой данных.
С появлением локальных сетей, подключением таких сетей к Интернет, созданием внутрикорпоративных, сетей, появляется возможность с любого рабочего места организации получить доступ к информационному ресурсу сети. Однако, при попытке использовать существующие БД возникают проблемы связанные с требованием к однородности рабочих мест (для запуска "родных" интерфейсов), сильнейшим трафиком в сети (доступ идет напрямую к файлам БД), загрузкой файлового сервера и невозможностью удаленной работы (например, командированных сотрудников). Решением проблемы могло бы стать использование унифицированного интерфейса WWW для доступа к ресурсам организации.
Технология World Wide Web, в переводе "Всемирная паутина", получила столь широкое распространение из-за простоты своих пользовательских интерфейсов. Принцип "жми на то, что интересно", лежащий в основе гипертекста, интуитивно понятен. В технологиях WWW все ключевые понятия просматриваемого документа: слова, картинки - имеют возможность "раскрыться" новым документом, развивающим это понятие. Такой способ представления информации называется "гипертекстом", а документы, представленные в таком виде - "гипертекстовыми документами". Для описания этих документов используется специальный язык - язык описания гипертекстовых документов или HTML (англ. вариант HyperText Markup Language).
Из этих предпосылок возникает задача преобразования накопленных данных в гипертекстовые документы WWW, задача поддержки актуальности преобразованной структуры. Другими словами, задача предоставления WWW - доступа к существующим базам данных.
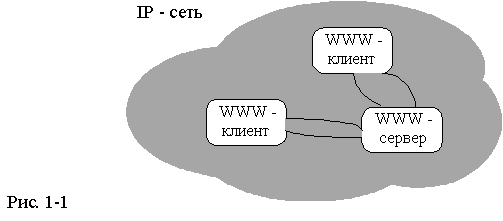
Использование технологий WWW для обеспечения доступа к каким-либо информационным ресурсам подразумевает существование следующих компонент (см.рис.1-1):
Передаваемые гипертекстовые документы оформляются в стандарте HTML - языке описания гипертекстовых документов. Эти документы могут либо храниться в статическом виде (совокупность файлов на диске), либо динамически компоноваться в зависимости от параметров запроса специальным программным обеспечением. Для динамической компоновки HTML-документов, WWW-сервер использует специальным образом оформленные программы- CGI-программы.
В состав специфики конкретной БД входят как технологические основы, такие как тип СУБД, вид интерфейсов, связи между таблицами, ограничения целостности, так и организационные решения, связанные с поддержкой актуальности баз данных и обеспечением доступа к ней.
При обеспечении WWW-доступа к существующим БД, возможен ряд путей - комплексов технологических и организационных решений. Практика использования WWW-технологии для доступа к существующим БД предоставляет широкий спектр технологических решений, по разному связанных между собой - перекрывающих, взаимодействующих и т.д. Выбор конкретных решений при обеспечении доступа зависит от специфики конкретной СУБД и от ряда других факторов, как то: наличие специалистов, способных с минимальными издержками освоить определенную ветвь технологических решений, существование других БД, WWW-доступ к которым должен осуществляться с минимальными дополнительными затратами и т.д.
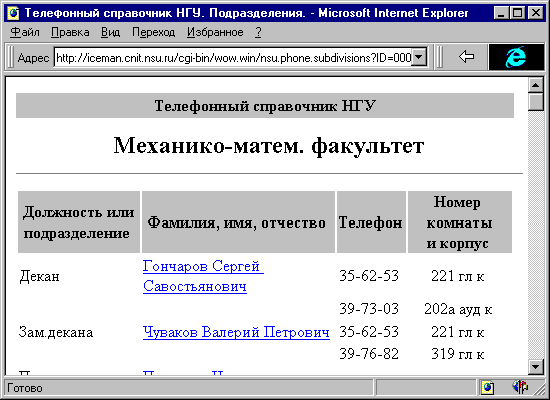
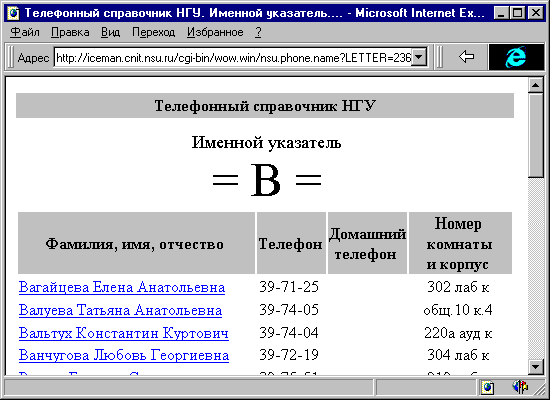
WWW - доступ к существующим базам данных может осуществляться по одному из трех основных сценариев. Ниже дается их краткое описание и основные характеристики.
В этом варианте содержимое БД просматривает специальная программа, создающая множество файлов - связных HTML-документов (см.рис.1-2). Полученные файлы могут быть перенесены на один или несколько WWW-серверов. Доступ к ним будет осуществляться как к статическим гипертекстовым документам сервера.
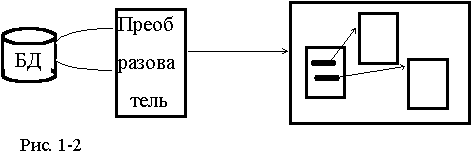
Этот вариант характеризуется минимальными начальными расходами. Он эффективен на небольших массивах данных простой структуры и редким обновлением, а также при пониженных требованиях к актуальности данных, предоставляемых через WWW. Кроме этого, очевидно полное отсутствие механизма поиска, хотя возможно развитое индексирование.
В качестве преобразователя может выступать программный комплекс, автоматически или полуавтоматически генерирующий статические документы. Программа-преобразователь может являться самостоятельно разработанной программой либо быть интегрированным средством класса генераторов отчетов.
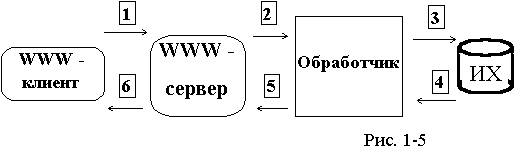
В этом варианте доступ к БД осуществляется специальной CGI-программой, запускаемой WWW-сервером в ответ на запрос WWW - клиента. Эта программа, обрабатывая запрос, просматривает содержимое БД и создает выходной HTML-документ, возвращаемый клиенту (см.рис.1-3).
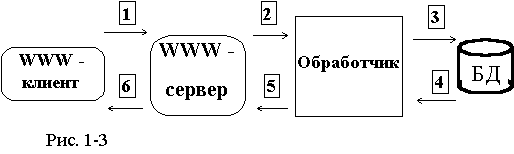
Это решение эффективно для больших баз данных со сложной структурой и при необходимости поддержки операций поиска. Показаниями также являются частое обновление и невозможность синхронизации преобразования БД в статические документы с обновлением содержимого. В этом варианте возможно осуществлять изменение БД из WWW-интерфейсов.
К недостаткам этого метода можно отнести большое время обработки запросов, необходимость постоянного доступа к основной базе данных, дополнительную загрузку средств поддержки БД, связанную с обработкой запросов от WWW - сервера.
Для реализации такой технологии необходимо использовать взаимодействие WWW-сервера с запускаемыми программами CGI - Common Gateway Interface. Выбор программных средств достаточно широк - языки программирования, интегрированные средства типа генераторов отчетов. Для СУБД со внутренними языками программирования существуют варианты использования этого языка для генерации документов.
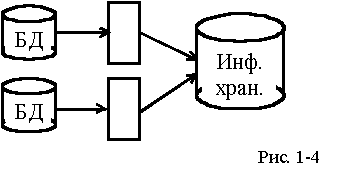
В этом варианте предлагается использование технологии, получившей название "информационного хранилища" (ИХ). Для обработки разнообразных запросов, в том числе и от WWW-сервера, используется промежуточная БД высокой производительности (см. рис.1-5). Информационное наполнение промежуточной БД осуществляется специализированным программным обеспечением на основе содержимого основных баз данных (см. рис.1-4).
Данный вариант свободен ото всех недостатков предыдущей схемы. Более того, после установления синхронизации данных информационного хранилища с основными БД возможен перенос пользовательских интерфейсов на информационное хранилище, что существенно повысит надежность и производительность, позволит организовать распределенные рабочие места.
Несмотря на кажущуюся громоздкость такой схемы, для задач обеспечения WWW-доступа к содержимому нескольких баз данных накладные расходы существенно уменьшаются.
Основой повышения производительности обработки WWW-запросов и резкого увеличения скорости разработки WWW-интерфейсов является использование внутренних языков СУБД информационного хранилища для создания гипертекстовых документов.
Для загрузки содержимого основной БД в информационное хранилище могут использоваться все перечисленные решения (языки программирования, интегрированные средства), а также специализированные средства перегрузки, поставляемые с SQL-сервером и продукты поддержки информационных хранилищ.
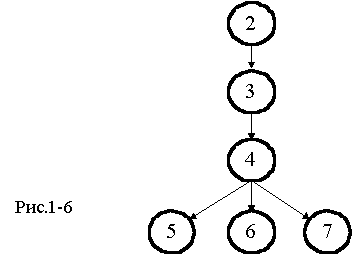
В главах отчета будут подробно освещены различные этапы приведенных сценариев, технологические решения, используемые для поддержки этих этапов. Взаимосвязь глав отчета показывает схема на рис. 1-6.
Во второй главе подробно описывается язык HTML. Она необходима для понимания того, какой вид должна иметь информация, представляемая с использованием технологий WWW.
Третья глава посвящена описанию базовых элементов WWW-технологии, процедур установки и администрирования WWW-сервера.
Четвертая глава содержит материал по корневой технологии создания динамических HTML-документов - интерфейсу CGI. Подробно описывается интерфейс CGI WWW-сервера с вызываемыми программами. Именно CGI-программы (программы, удовлетворяющие спецификации CGI) способны динамически обрабатывать WWW - запросы к базам данных.
В главах 5, 6, 7 излагается три технологических направления, используемых при реализации приведенных выше сценариев. Сориентировавшись на одно или несколько таких направлений, можно реализовывать программные комплексы с функциями "Преобразователь" и "Обработчик" сценариев 1-3.
Предлагаемые технологические решения обладают универсальностью области применения. Одно решение может использоваться для:
Как было сказано ранее, одним из ключевых элементов технологии WWW является WWW-сервер. Стандартом де-факто для Unix-систем стало программное обеспечение (ПО) WWW-сервера Национального Центра по Суперкомпьютерным Приложениям (NCSA) Иллинойского Университета. Все вновь создаваемые продукты поддерживают полную совместимость с ПО NCSA по режимам работы и форматом данных. Cервер NCSA является постоянно совершенствуемым продуктом, отражающим последние веяния WWW-технологии. Созданная относительно недавно "Apache Group" разрабатывает свое программное обеспечение WWW - сервера на базе продукта NCSA HTTPD.
Глава 3 данного отчета посвящена установке и администрированию WWW-сервера NCSA HTTPD.
При реализации сценария 3 встает вопрос о выборе качественной платформы для создания информационного хранилища. Реляционная система управления базами данных фирмы Oracle является лидером на рынке СУБД. По производительности, надежности хранения данных, развитию семейства интерфейсов, объему серверных платформ продукты Oracle возглавляют многочисленные рейтинги. Гибкость использования, развитые средства управления доступом и распределенная архитектура делают сервер Oracle чрезвычайно привлекательным для технологии информационных хранилищ, а возможность работы на свободно - распространяемых Unix-платформах расширяет его возможности в некоммерческой среде.
Существенным ограничением использование Oracle в сфере науки и образования является достаточно высокая цена и низкое бюджетное финансирование. Однако с 1996 года фирма Oracle объявила о специальной программе для российских университетов, что позволяет за относительно небольшие деньги приобрести любой набор продуктов Oracle.
Одной из основных технологий создания CGI-модулей для реализации функций "преобразователя" и "обработчика" сценариев 1-3 является язык C. Язык C - наиболее распространенный язык программирования. В каждом ВУЗе есть специалисты, способные использовать его для создания приложений. При решении описанных задач язык C можно использовать для создания следующих программ:
Для поддержки этих функций создано большое количество библиотек и функций языка C, готовых приложений в исходных текстах. В главе 4 описывается использование языка C для создания исполняемых CGI-программ.
Язык Perl был создан для повышения эффективности обработки текстовых документов. Он ориентирован на обработку строк. В настоящее время язык получил большое распространение как инструмент создания исполняемых модулей WWW-сервера. Существующие пакеты расширения обеспечивают доступ к SQL-серверам непосредственно из Perl-программы. Это позволяет использовать его для решения всех задач, возникающих при обеспечении WWW-доступа к базам данных. Perl эффективен также при обработке произвольных структур данных: существующих отчетов, списков, карточек в электронном виде.
В главе 6 приведены примеры использования его для создания HTML - документов, доступа к SQL-серверам, dbf-ориентированным базам данных. В Приложении 2 описаны все основные конструкции языка.
Пакет WOW является свободно-распространяемым программным средством, предназначенным для создания интерактивных WWW-интерфейсов с СУБД Oracle. Пакет WOW был первым и наиболее простым средством, выпущенным фирмой Oracle. В настоящее время существует набор продуктов, развивающих функциональность WOW'а - Oracle Web Server версий 1, 2, Oracle Web Arcitecture.
Все перечисленные продукты позволяют использовать процедурное расширение языка SQL - PL/SQL, разработанное фирмой Oracle для динамического создания гипертекстовых документов. Высокая скорость разработки достигается за счет резкого упрощения доступа к БД - программы на PL/SQL исполняются самим сервером Oracle. Предлагаемый пакет WOW был переработан в Новосибирском областном центре НИТ с целью поддержки нескольких русскоязычных кодировок.
Основной областью использования WOW является обработка запросов от WWW-сервера к SQL-серверу Oracle в среде Unix. В предложенных сценариях пакет WOW позволит организовать эффективный WWW доступ к информационному хранилищу, построенному на базе сервера баз данных Oracle (сценарий 3). Глава 7 отчета посвящена описанию процедур установки и администрирования пакета.
Пакет предназначен для использования под ОС Windows и позволяет обращаться к различным базам данных, поддерживающим интерфейс ODBC через WWW-интерфейсы. Пакет имеет коммерческий статус, его "evaluation copy" является свободно-распространяемой. Для доступа к базам данных используются конструкции языка DBML - расширения языка HTML, дополненного средствами доступа к БД через ODBC. Документы на языке DBML обрабатываются на серверной части, в результате чего создается HTML-документ. Полноценная версия пакета, вместе с WWW - сервером стоит $486.
Пакет может эффективно использоваться в качестве обработчика запросов WWW к исходным базам данных или информационному хранилищу (сценарии 2,3). Глава 5 отчета посвящена описанию процедуры установки и использованию пакета.
Трудоемкость обеспечения WWW-доступа к базам данных, очевидно, складывается из трудоемкости работ при реализации одного из вышеприведенных сценариев. Реализация первого сценария связана с последовательным преобразованием всех данных, находящихся в исходной БД. Разработка средств вывода содержимого таблицы в формате HTML с необходимым форматированием и текстовым сопровождением будет занимать порядка 1-3-х дней для одного разработчика. Разработка средств построения индексной структуры к выводимым данным является более творческой работой и может занять 1-3 недели для одного разработчика.
Трудоемкость построения интерфейсов для сценариев 2, 3, в общем случае, эквивалентна трудоемкости построения этих интерфейсов при создании исходной информационной системы (т.е. той, для которой обеспечивается WWW-доступ) с использованием традиционных средств разработки (не-CASE). В третьем сценарии дополнительные трудозатраты пойдут на перегрузку данных в ИХ. При перегрузке данных без изменения структуры и имен можно исходить из оценки трудозатрат: 1-2 таблицы в 1-2 дня для одного разработчика, в зависимости от сложности и объема таблиц, при условии отладки технологии перегрузки.
При использовании различных средств разработки интерфейсов к БД, представленных в отчете, трудозатраты могут существенно различаться. Ранжированный по уменьшению трудозатрат на разработку интерфейсов список будет выглядеть так:
2.1 Введение
2.2 Язык HTML
2.2.1 Структура HTML-документов
2.2.2 Теги HTML
2.2.2.1 Заглавные теги
2.2.2.2 Форматирующие теги
2.2.2.3 Комментарии
2.2.2.4 Заголовки
2.2.2.5 Шрифты
2.2.2.6 Списки
2.2.2.7 Цитаты и преформатированный текст
2.2.2.8 Адреса
2.2.2.9 Гипертекстовые ссылки
2.2.2.10 Верстка таблиц
2.2.2.11 Картрированные изображения
2.2.2.12 Специальные символы
2.2.3 Расширения программ просмотра
2.2.3.1 Обзор расширений
2.2.3.2 Расширения Netscape Navigator
2.2.3.3 Расширения MS Internet Explorer
2.2.3.4 Рамки (фреймы)
Web-страницы описываются на специальном языке, называемом HTML (HyperText Markup Language, Язык разметки гипертекстовой информации), ставшем основным языком описания документов в Internet. HTML является простым подмножеством универсального языка разметки документов SGML (Standard Generalized Markup Language, Стандартный язык разметки документов), являющегося стандартом для обмена документами между различными платформами. Точнее, весь синтаксис HTML полностью описывается с помощью SGML DTD (Document Type Definition). По этой причине почти все программы, совместимые с SGML, могут быть использованы при подготовке HTML-документов.
За сравнительно короткое время разработчики Web-страниц прошли путь от простого перевода текстовых документов на язык HTML до создания красочных, искусно оформленных интерактивных страниц, с умело используемой графикой и различными стилями размещения текста на странице. Появилась профессия под названием ``Web-дизайнер'', то есть человек, специализирующийся на создании Web-страниц высшего качества. Некоторые современные Web-страницы можно со всей ответственностью назвать произведениями искусства.
Интересно отметить некоторые особенности, отличающие верстку информации для Web и верстку для ``обычной'', то есть, бумажной технологии передачи документов. В отличие от языков описания печатных документов, вроде известного языка PostScript, упор делается на переносимость информационного наполнения страниц, а не их внешнего оформления. Поясним сказанное на примере: при переносе документа на языке PostScript между двумя компьютерами гарантируется сохранение его внешнего вида, то есть размеров, шрифтового оформления; тогда как для HTML-документов гарантируется лишь сохранение логической структуры. Это происходит потому, что никто не гарантирует, что устройство, на котором пользователь будет просматривать Web-страницу, не окажется черно-белым алфавитно-цифровым терминалом 1970-го года выпуска! Или же что программа просмотра, используемая пользователем, способна корректно отобразить графические вставки в различных форматах. И поэтому Web-дизайнер несет особую ответственность за представление информации на своих страницах.
Web-страницы описываются на специальном языке, называемом HTML (HyperText Markup Language, Язык разметки гипертекстовой информации), который позволяет осуществлять простое форматирование текста, вставку графики, а также составление таблиц и цветовое оформление документов.
Будучи подмножеством языка SGML, HTML имеет теговую структуру. Это означает, что в тексте встречаются комманды, изменяющие интерпретацию информации. Например, слово, напечатанное курсивом, в исходном тексте выглядит так:
слово, напечатанное <I>курсивом</I>.
Теги записываются в угловых скобках и могут содержать дополнительные параметры. Большинство тегов располагается в виде ``скобок'' вокруг текста (как теги <I> и </I> вокруг слова ``курсивом'' в приведенном выше примере). Благодаря этому свойству, теги можно подразделить на открывающие и закрывающие. Не у всех тегов существуют соответствующие им закрывающие, такие теги иногда называют ``пустыми''(empty). Общую структуру открывающего тега можно записать так:
<NNNNN Name="Value" .....>Соответствующий закрывающий тег быдет иметь вид
</NNNNN>Далее под словом ``тег'' мы будем понимать совокупность открывающего и соответствующего ему закрывающего (если таковой существует) элементов.
Рассказ о тегах языка HTML поведем на примере создания некоторой Web-страницы. Пусть перед нами стоит задача сделать страницу, посвященную некоторой личности (например, самому читателю), тогда такая Web-страница будет называться ``домашней'' (homepage). Сейчас будут рассмотрены теги языка, а применение их на странице будет оставлено Читателю в качестве упражнения.
Начиная писать HTML-документ, имеет смысл идентифицировать его как таковой. Такая идентификация достигается путем вставления в самое начало документа тегов <!DOCTYPE HTML PUBLIC ``-//W3C//DTD HTML 3.2//EN''> и <HTML> (соответственно, в конец документа, закрывающего тега </HTML>; никогда не забывайте закрывать скобки!). Тег DOCTYPE является тегом языка SGML и объявляет, что документ будет описан в соответствии со спецификацией HTML 3.2. Тег HTML указывает на начало документа. Теперь пора подумать об информационном наполнении. Начнем, естественно, с заголовка. Заголовок HTML-файла находится в обязательной секции <HEAD>, которая должна находиться в самом начале, то есть сразу после тега <HTML>. Оформляется заголовок с помощью тега <TITLE>. Назовем наш документ ``The first homepage''. Ниже приведен листинг получившегося HTML-документа:
<HTML> <HEAD> <TITLE>The first homepage</TITLE> </HEAD> </HTML>
Попробуем просмотреть этот файл с помощью какой-нибудь программы просмотра, например, Navigator фирмы Netscape Communications Corp. После загрузки экран программы остался пустым. ``А где же заголовок?'',- спросит возмущенный читатель. Присмотритесь повнимательней к ЗАГОЛОВКУ ОКНА программы просмотра в оконной системе и убедитесь, что заголовок отображен именно там. Тег <TITLE> позволяет задавать название для всего документа. Это название будет появляться в заголовке окна программы просмотра, а также будет появляться в списке закладок (bookmarks, shortcuts в различных терминологиях) при создании таковых.
Другими элементами секции <HEAD>...</HEAD> являются:
<BASE параметры> - тег для указания URL документа. Тег имеет такие параметры:
HREF - указывает базовый URL для документа. Замечание: URL должен быть указан в полной форме.
TARGET - указывает окно для отображения документов, на которые ссылается данный документ.
<STYLE> - тег, зарезервированный для использования в будущем для так называемых ``стилей'' (stylesheets). Точный синтаксис тега пока недокументирован.
<META параметры> - тег, который теоретически должен использоваться для включения в документ некой специфичной информации для программ-индексаторов, каталогизаторов и т. д. Кроме того, у него есть несколько полезных параметров, позволяющих страницам сменять друг друга по прошествии определенных промежутков времени. Тег имеет следующие параметры:
HTTP-EQUIV=``refresh'' - указывает программе просмотра, что нужно перепрыгнуть на страничку, указанную в параметре CONTENT по прошествии указанного там же промежутка времени.
CONTENT=``number; url=URL'' - задает временной интервал number и URL для команды HTTP-EQUIV=``refresh''.
NAME=``description'' или NAME=``keywords'' - указывает серверу, как интерпретировать параметр CONTENT - как описание документа или как список ключевых слов.
CONTENT=``text или список значений'' - это не опечатка. У параметра CONTENT два смысла: один для команды HTTP-EQUIV=``refresh'', другой для команды NAME. В последнем случае значение параметра определяет либо описание документа (если параметр NAME=``description''), либо список разделенных запятыми ключевых слов (если параметр NAME=``keywords'').
Теперь перейдем к оформлению содержимого документа. В терминах HTML содержимое документа называется его ТЕЛОМ, или по-английски - BODY. Именно так и называется тег, в поле действия которого находится все содержимое (то есть, оно заключено между внутри тега <BODY>...</BODY>). Тег <BODY>...</BODY> может содержать дополнительные параметры, позволяющие изменить цвета, используемые в документе или назначить фоновую картинку:
BGCOLOR - определяет цвет фона документа. Цвет может быть задан как RGB-триплет (см. Приложение П1 к отчету) (например, BGCOLOR="#FFFFFF"--белый цвет), или быть одним из предопределенных символьных имен:
aquablackbluefuchsia
gray green lome maroon
navy olive purple red
silver teal white yellow
BACKGROUND - позволяет задать фоновую картинку для документа. Картинка будет размножена (tiled) и покроет всю видимую площадь области отображения окна программы просмотра.
TEXT - задает цвет текста документа. Цвет задается так же как и для параметра BGCOLOR.
LINK - задает цвет для текста и рамок изображений в активных зонах документа, содержащих ссылки (anchors).
VLINK - (Visited LINKs color) задает цвет для ранее выбранных ссылок.
ALINK - (Active LINKs color) задает цвет для ссылок в момент выбора.
Если теперь набрать внутри тела документа несколько строк текста,
а потом просмотреть его в браузере (мы будем использовать этот англоязычный
термин вместо длинного ``программа просмотра''), то в окне появится текст, написанный простым мелким шрифтом, причем имеющиеся в исходном тексте переводы строк не сохранятся. Браузеры сами ``заливают'' текст на страницу, исходя при этом из доступной
ширины окна. Для того чтобы вставить ``насильный'' перевод строки, необходимо
воспользоваться тегом <BR> . При отображении браузер переведет строку
на месте появления этого тега.
ВНИМАНИЕ! ТЕГ <BR> ИСПОЛЬЗУЕТСЯ БЕЗ ЗАКРЫВАЮЩЕГО ЭЛЕМЕНТА </BR>. В HTML есть еще несколько тегов, обладающих подобным свойством. Их обычно называют пустыми, так как они не содержат ``внутреннего'' наполнения.
Если вам необходимо сделать так, чтобы в определенном месте текст НЕ МОГ быть разорван, напишите в этом месте тег <NOBR>
Для разбивки текста на параграфы используется тег
<P параметры>
Точнее, параграф помещается внутрь тега <P>...</P>, но так как вложенных параграфов не бывает, можно пропускать закрывающий тег
перед любым другим тегом, вызывающим вертикальный разрыв в тексте (такие теги
мы в дальнейшем будем называть блочными).
Тег <P> имеет один параметр ALIGN, указывающий на способ выравнивания текста внутри параграфа: текст может быть выровнен по правому (RIGHT), левому (LEFT) краям или отцентрирован (CENTER). Если параметр опущен, текст выравнивается по левому краю.
Чтобы отцентрировать параграф можно также пользоваться тегом
<CENTER>...</CENTER>
Еще одним способом разделения текста на части можно назвать горизонтальную линию. Линия является элементом языка HTML
и вставляется в текст посредством тега
<HR параметры>,
где параметры могут быть следующими:
WIDTH - задает ширину линии. Единицей измерения в HTML считается точка устройства вывода, то есть, указав в качестве параметра тегу <HR> WIDTH=100, вы создадите линию шириной 100 точек. Очевидно, что такой способ не очень удобен, так как документ может быть отображен на устройствах с различной разрешающей способностью (количеством точек по горизонтали и по вертикали) по-разному. По этой причине в HTML существует возможность задавать ОТНОСИТЕЛЬНЫЕ размеры элементов, то есть процент от общей ширины области отображения (окна браузера или листа бумаги). Пример: указав в качестве параметра тегу <HR> WIDTH=50%, вы получите линию в половину области отображения документа.
SIZE - задает толщину линии.
NOSHADE - если этот параметр задан, линия не будет иметь тени.
Как и во всяком языке программирования, в HTML есть способ закомментировать часть текста так, чтобы она не обрабатывалась программами просмотра. Комментарии заключаются между последовательностями < ! - - и - - >. Пример комментария:
<!-- этот текст закомментирован -->
Если посмотреть на получившуюся к этому моменту страницу, то она покажется однотонной и малопривлекательной. С первого взгляда даже непонятно, о чем она (если не смотреть на заголовок окна). Странице не хватает ``настоящего'' заголовка, то есть, заголовка в теле самого документа. HTML различает шесть различных видов заголовков. Для их создания используются теги <H1>...</H1>,...,<H6>...</H6>. Название тегов происходит от английского слова Heading (то есть, заголовок) что определяет их использование. Размер 1 соответствует самому крупному шрифту, размер 6 самому мелкому. Итак, озаглавим нашу страницу, напишем перед основным текстом строчку
<H1>Welcome to my homepage!</H1>
Теперь просмотрим нашу страницу в браузере. Теперь страница смотрится гораздо лучше чем раньше. Теги <Hn> являются блочными: в месте их применения происходит разрыв абзацев.
Другими средствами шрифтового оформления текста являются выделения курсивом и жирным шрифтом. Таким способом очень удобно выделять отдельные слова в тексте, а также, создавать заголовки. Например, очень удобно заголовки первого и второго уровней оформлять с помощью тегов <Hn>, а заголовки третьего уровня выделить жирным шрифтом. Выделение курсивом осуществляется с помощью тега <I> (от слова Italic), а жирным шрифтом -- с помощью тега <B> (от слова Bold).
В HTML есть также понятие emphasis - обобщенное выделение. Оформляется оно с помощью тега <EM>...</EM>. Такое выделение - средство описания логической структуры документа. Обычно выделенный таким способом текст отображается курсивом.
Другим средством логического выделения можно считать тег
<STRONG>...</STRONG>
Он используется для усиления участков текста. Содержимое тега обычно отображается жирным шрифтом.
Изменить размеры и цвет шрифтов можно с помощью тега
<FONT параметры>...</FONT>
Параметры могут быть следующими:
SIZE=``value или value'' - задает абсолютный или относительный размер шрифта. Относительный размер задается по отношению к базовому размеру (см. далее). Диапазон принимаемых значений -- от одного до семи.
COLOR - указывает цвет для текста.
FACE - расширение Microsoft Internet Explorer и Netscape Navigator. Позволяет задать гарнитуру (или список гарнитур, из имеющихся в системе шрифтов будет выбран наиболее подходящий) для текста. Конечный результат зависит от количества и разнообразия шрифтов, установленных в системе. Пример:
<FONT FACE="Arial, Times Roman">
Пример выделения текста другой гарнитурой.
</FONT>
Базовый размер шрифта для всего документа можно задать с помощью тега
<BASEFONT параметры>. Параметр всего один:
SIZE - задает размер шрифта.
Для того чтобы действительно привлечь пользователя, иногда может потребоваться
мигающий текст. Заставить текст мигать можно, заключив его внутрь тега
<BLINK>...</BLINK>
Пользоваться этим тегом надо с некоторой осторожностью, так как не всегда приятно наблюдать мигающие объекты.
Списки в HTML бывают трех типов: ненумерованные, нумерованные и
так называемые списки терминов. Ненумерованный список оформляется с помощью блока
<UL>
<LI> элемент
<LI> элемент
...
</UL>
Список будет отображен примерно так:
Нумерованный список отличается от ненумерованного тем, что около
пунктов вместо жирных точек вставляются порядковые номера пунктов.
Оформляется он в виде блока
<OL>
<LI> элемент
<LI> элемент
...
</OL>
Отобразится он в таком виде:
Третим видом списка является список терминов. Он очень удобен для
оформления всевозможных глоссариев. Оформить такой список можно с помощью блока
<DL>
<DT>Термин1 <DD>Описание1
<DT>Термин2 <DD>Описание2
...
</DL>
Вид у полученного списка будет примерно следующий:
Термин1
Описание1
Термин2
Описание2
...
Иногда возникает ситуация, когда необходимо вставить в документ цитату, исходный текст программы или просто текстовый документ, где формат имеет значение и нежелательно, чтобы Web-браузер сам пытался вставлять переводы строк там, где он хочет. Язык HTML имеет для возможности для всех эти случаев.
Цитаты в HTML оформляются с помощью тега
<BLACKQUOTE> ... </BLACKQUOTE>
Браузер выделит цитату каким-либо способом, например шрифтом и/или вставит
горизонтальные отступы справа и слева.
Чтобы вставить в документ исходный текст можно воспользоваться тегом
<CODE> ... </CODE>
Текст будет выделен шрифтом фиксированной ширины.
Случай, когда в документе необходимо присутствие текста с фиксированным
форматом особенно распространен. Часто такая возможность применяется,
например, при включении в текст содержимого электронных писем или статей из
сети Usenet. Оформляется все это с помощью тега
<PRE>
текст1
...
...
текстN
</PRE>
При этом отображен он будет, по возможности, примерно так:
текст1 ... ... текстN
В HTML есть средство для оформления адресов (адрес будет, по возможности,
выделен шрифтом). Конечно, никто не заставляет пользоваться этой возможностью, но без ее описания наша книга не была бы полной.
Адрес оформляется с помощью тега
<ADDRESS> ... </ADDRESS>
Браузеры обычно выделяют его курсивом, то есть строка <ADDRESS> ул. Пирогова, д. 2 </ADDRESS> будет отображена как
ул. Пирогова, д. 2.
Одной из самых мощных возможностей WWW является возможность организации
гипертекстовых связей между документами. Прежде чем описывать средства
языка HTML для организации таких связей, следует рассказать об идентификации
ресурсов в Internet. Объемы информации в Internet огромны, и существует
множество способов доступа к ним. Для указания местоположения отдельного
ресурса используется запись под названием URL (Uniform Resource Locator). Она описывает способ доступа к ресурсу и его местоположение.
URL имеет вид:
метод://[имя-пользователя@][хост][:порт][имя-ресурса],
где
метод идентифицирует метод обращения к ресурсу,
имя-пользователя указывает на учетное имя пользователя в системе, обычно предполагается анонимный доступ.
хост указывает сетевое имя (или сетевой адрес) хоста, на котором содержится ресурс.
порт: номер порта для доступа к сервису.
имя-ресурса идентифицирует ресурс на хосте и зависит от метода доступа.
Существуют идентификаторы способов доступа к ресурсам для большинства сервисов Internet. Обозначения таковы:
http - для доступа по протоколу HTTP, используемому в WWW.
ftp - для доступа по протоколу FTP.
telnet - для доступа по протоколу telnet, эмуляция терминала.
gopher - для доступа к Gopher-серверам.
wais - для доступа к WAIS (Wide Area Information System).
news - для доступа к новостям Usenet.
file - для доступа к локальным файлам.
Чтобы оформить какой-либо элемент документа в качестве гипертекстовой
ссылки, достаточно лишь заключить его внутрь тега <A> (anchor).
Полный синтаксис тега таков:
<A параметры>
....
</A>
где параметры могут быть следующими:
HREF - обязательный параметр, определяет или URL или файл, на который мы ссылаемся. Если мы ссылаемся на файл, то поле HREF содержит имя файла в файловой системе Web-сервера.
NAME - если этот параметр указан, то ссылка никуда не ссылается. Неочевидно, но в этом случае тег <A> указывает именованную метку в документе, на которую потом можно будет сослаться используя символ # в параметре HREF.
target - параметр, указывающий имя окна или рамки в которой будет отображен документ. Если окна или рамки с таким именем не существует, будет открыто новое окно.
Таблицы являются мощнейшим средством HTML для верстки страниц. До появления в языке HTML средств верстки таблиц, нельзя было создать даже самый простой многоколончатый текст или сводную таблицу, то после появления такой возможности Web-дизайнеры стали использовать ее в полной мере и добиваться сложных эффектов.
Создается таблица с помощью конструкции
<TABLE параметры >
<CAPTION>Заголовок</CAPTION>
<TR параметры>
<TD параметры>
...
</TD>
....
</TR>
</TABLE>
Тег TABLE начинает описание таблицы и может иметь следующие параметры:
BORDER - определяет толщину рамки таблицы. Если указано нулевое значение то рамка не отображается. Если этот параметр не указан, его значение считается нулевым (рамка не отображается).
WIDTH, HEIGHT - указывает размеры таблицы, если они должны быть жестко заданы.
ALIGN - определяет, как должна быть выровнена таблица: справа (RIGHT), слева (LEFT) или в центре (CENTER) страницы.
CELLSPACING - число точек между отдельными ячейками в таблице.
CELLPADDING - число точек между рамкой и содержимым ячейки.
С помощью тега <TR параметры>...</TR> оформляются строки таблиц.
Он может иметь следующие параметры:
ALIGN - используется для задания способа горизонтального форматирования данных внутри ячеек: они могут прижиматься к правому (RIGHT), левому (LEFT) краям или центрироваться (CENTER).
VALIGN - используется для задания способа вертикального форматирования данных внутри ячеек: они могут прижиматься к верхнему (TOP), нижнему (BOTTOM) краям, центрироваться (MIDDLE) или иметь общую базовую линию (BASELINE).
Конкретные ячейки задаются с помощью тега <TD параметры>...</TD>, где параметры могут быть следующими:
WIDTH - задает ширину ячейки.
COLSPAN - определяет, сколько колонок таблицы ячейка будет перекрывать.
ROWSPAN - определяет, сколько строк таблицы ячейка будет перекрывать.
NOWRAP - если этот параметр указан, содержимое ячеек не будет переноситься, чтобы влезать в ширину ячейки.
BGCOLOR - параметр, поддерживаемый современными браузерами: указывает цвет фона ячейки в виде RGB-триплета или символьного имени.
Еще один тег для оформления ячеек таблиц - тег <TH>...</TH> - нужен для задания заголовочных ячеек. Он во всем совпадает с тегом <TD>, но в отличие от него, содержимое выдается жирным шрифтом и центрируется.
Если нужно задать заголовок ВСЕЙ таблицы, используйте тег <CAPTION параметры>...</CAPTION>. Он должен быть внутри тега <TABLE>, но вне описания ячеек. Тег имеет один параметр:
ALIGN - указывает положение заголовка: он может быть в верхней (TOP) или нижней (BOTTOM) части таблицы.
Пример:
<TABLE BORDER=1 CELLSPACING=2 CELLPADDING=1 WIDTH=500> <TR> <TD COLSPAN=3 ALIGN=CENTER>A</TD> </TR> <TR> <TD ROWSPAN=2 ALIGN=CENTER WIDTH="30%">B</TD> <TD ROWSPAN=2 ALIGN=CENTER WIDTH="40%">C</TD> <TD ALIGN=CENTER WIDTH="30%">D</TD> </TR> <TR> <TD ALIGN=CENTER>E</TD> </TR> </TABLE>
Очень мощным средством организации гипертекстовых ссылок является так называемые ``картрированые изображения'' (imagemaps). Они представляют собой изображения с чувствительными областями, то есть, выделение различных частей изображения указательным устройством приводит к движению по гипертексту в различных ``направлениях''.
Картрированные изображения бывают двух типов: обрабатываемые на сервере (server-side) или на клиенте (client-side).
Для создания карт на стороне клиента используется тег HTML под названием
<MAP>. Синтаксис тега таков:
<MAP NAME=``имя карты''>
<AREA параметры>
...
<AREA параметры>
</MAP>
где параметры тега <AREA> могут быть такими:
SHAPE - определяет форму активной области для карты. Может принимать значения RECT, CIRCLE, POLY, DEFAULT, соответствующие областям прямоугольной, круглой, многоугольной и области по умолчанию соответственно. Все типы областей, кроме DEFAULT, требуют указания координат в атрибуте COORDS.
COORDS - определяет координаты областей. В зависимости от типа области может иметь вид: для прямоугольной--значения координат верхнего левого и правого нижнего углов, (``x1,y1,x2,y2''); для круговой--координаты центра и радиус (``x,y,r''); для многоугольной--список координат вершин (``x1,y1,x2,y2,x3,y3,...'');
HREF - определяет URL, на который ссылается данная область.
NOREF - указывает, что область ``мертва'', то есть за ней не скрывается ссылка.
Чтобы использовать локальную карту на изображении в параметре USEMAP тега <IMG> необходимо указать имя карты. Например:
<MAP NAME="mymap">
<AREA SHAPE="RECT" COORDS="420,220,520,260" HREF=\\
"http://www.some.com/rect/">
<AREA SHAPE="CIRCLE" COORDS="320,150,30" HREF=\\
"http://www.some.com/circle">
<AREA SHAPE="POLY" COORDS="150,450,300,450,225,240" \\
HREF="http://www.some.com/poly">
<AREA SHAPE="DEFAULT" HREF="http://www.some.com/">
</MAP>
......
<IMG SRC="picture.gif" ALT="Imagemap" BORDER="0" WIDTH="640" \\
HEIGHT="480" USEMAP="#mymap">
даст примерно слежующую карту на изображении:
Для того, чтобы создать карту, обрабатываемую на сервере, необходимо административное вмешательство, так как на сервере придется изменять файл конфигурации для CGI-модуля обработки информации от карты.
При использовании различных Web-серверов формат описания карты
на сервере может варьироваться. Два наиболее распространенных формата
произошли от HTTP-серверов NCSA и CERN. Приведем пример использования
карты с сервером NCSA httpd.
На стороне сервера, файл (например) /usr/local/etc/httpd/conf/imagemap.conf:
# This is a map for NCSA server test_map : /home/joe/public_html/maps/test.mapИспользовать эту карту можно примерно таким образом:
<A HREF="http://www.myhost.domain/cgi-bin/imagemap/test_map"> <IMG SRC="test_img.gif" ALT="Server-side imagemap" WIDTH="320" \ HEIGHT=200 ISMAP></A>Ключевым в данном примере является слово ISMAP, которое указывает браузеру, что при активации изображения необходимо послать серверу информацию о координатах курсора указательного устройства относительно изображения, после чего ждать от сервера ответа в виде URL, на который браузер должен ``перейти''.
Видно, что для реализации карты, обрабатываемой сервером, требуется больше шагов, но иногда без карт такого рода просто не обойтись: например, когда требуется ТОЧНО знать координаты внутри изображения (скажем, когда обрабатывается какая-либо шкала).
Для создания карт существует множество программ для различных OS, например ImageMap компании Boutell.Com. Эта программа существует в версиях для MS Windows и для Linux.
Некоторые общеупотребимые символы не имеют своих мест на клавиатуре, например значок ©. Другие же трактуются браузерами как командные последовательности, как, например, угловые скобки, в которые заключаются теги языка HTML. Очевидно, должен быть способ набора таких символов в текст. В HTML существует набор макропоследовательностей, которые превращаются браузерами в соответствующие им ``непечатные'' символы. Очевидно, что не во всех шрифтах есть полный набор символов, и браузер не во всех ситуациях будет способен их корректно отобразить. Но для полного описания документа все особые символы должны быть правильно закодированы. Приведем список специальных символов и соответствующие им макрокоманды языка.
| & | & | Амперсанд |
| < | < | Левая угловая скобка |
| > | > | Правая угловая скобка |
Полный перечень всех специальных символов вместе с их кодами приведен в Приложении П1 к отчету.
Некоторые браузеры кроме поддержки базового языка HTML обладают также дополнительными возможностями.
Первым браузером, имевшим действительно значительные расширения стал Netscape Navigator. Популярность использования расширенных возможностей Netscape была настолько высока, что они вошли в новый проект стандарта HTML 3.2.
Его конкурент, Microsoft Internet Explorer, предоставляет разработчикам Web-страниц еще больший простор; но тот факт, что он функционирует лишь на одной платформе, делает разработку специфичных для него документов не очень привлекательной (если, конечно, ВСЕ пользователи ваших страниц не работают в Microsoft Windows и Internet Explorer).
Большинство мелких расширений представляют собой дополнительные параметры или значения параметров различных тегов. Они обсуждались нами во время обсуждения тегов HTML.
Самыми существенными расширениями, конечно, являются внутренние языки браузеров: JavaScript в Netscape Navigator и VBScript в MS Internet Explorer. Обсуждение этих языков выходит за рамки данной книги, их описания могут быть найдены на серверах их производителей.
Расширения Netscape Navigator в массе своей нашли отражение в проекте стандарта HTML 3.2. Тем не менее, компания Netsacape Communications Corp продолжает оснащать свой браузер все новыми и новыми возможностями. Мы не будем их здесь описывать так как браузер постоянно совершенствуется и меняется, поэтому рекоммендуется просто получать информацию о всех новейших возможностях прямо с узла Netscape .
Компания Microsoft оснастила свой продукт очень сложными эффектами и возможностями. Примеры: плавающие рамки, ``летающий текст'', встраиваемые компоненты ActiveX. К сожалению, большинство дополнительных возможностей программы Internet Explorer тесно связано с использованием Microsoft Windows, и являются непереносимыми. Так же как и о расширениях Navigator, читайте фирменные руководства по расширенному языку HTML на узле Microsoft
Мощным визуальным средством являются так называемые рамки или фреймы (frames). С помощью рамок область отображения браузера может быть разделена на отдельные части, содержащие различные документы. При этом возможно задание связей между рамками так, что выбор ссылки в одной рамке может приводить к отображению запрошенного документа в другой. Это позволяет создавать очень удобные в использовании документы (при неправильном применении можно также создать и очень неудобные). Рамки на сегодняшний день поддерживаются в последних версиях таких браузеров, как Netscape Navigator (начиная с версии 2.0) и MS Internet Explorer (версии 3.0 и выше), но популярность применения рамок растет, и похоже, что вскоре к этим браузерам добавятся новые.
Рамки описываются в специальном HTML-документе, называемом Документом Описания Рамок. Этот документ содержит описание числа, размеров и положения рамок, а также URL-и их содержимого. Нельзя пытаться вписать содержимое рамок в описание, оно должно находиться в отдельных документах.
При описании рамок тег <BODY> заменяется на тег
<FRAMESET параметры>
...
описания содержимого рамок
...
</FRAMESET>
Тег будет игнорироваться браузером, если перед ним встретятся
любые теги, в обычном случае встречающиеся внутри тега <BODY>.
Теги <FRAMESET> могут быть вложенными, что позволяет, как Читатель
увидит далее, создавать очень сложные конструкции.
Параметры тега <FRAMESET> могут быть следующими:
ROWS=``x1,x2,... или x1%,x2%,... или x1*,x2*,...'' - этот параметр описывает рамки как строки различной высоты. Высоты рамок задаются списком разделенных запятыми значений. Высоты измеряются в точках, процентном отношении от общей высоты области отображения, либо как относительные величины. Сумма высот всех рамок должна быть равна высоте всей области отображения. Если этого не происходит, браузеры сами корректируют значения.
COLS=``x1,x2,... или x1%,x2%,... или *'' - используется для описания рамок как столбцов различной ширины. Используется так же, как параметр ROWS.
Примеры:
<FRAMESET ROWS="3*,*">задаст две горизонтальные рамки, причем первая (верхняя) будет в три раза выше второй (нижней).
<FRAMESET ROWS="100,*,50">задаст три горизонтальные рамки, причем первая (верхняя) будет иметь высоту 100 точек, третья (нижняя) будет иметь высоту 50 точек, а вторая (средняя) займет все оставшееся пространство.
<FRAMESET COLS="70%,30%">задаст две вертикальные рамки, причем первая (левая) будет иметь ширину 70% общей ширины области отображения, а вторая (правая) -- 30%.
Для задания содержимого рамки используется тег <FRAME параметры>.
Параметры могут быть следующими:
SRC - указывает URL документа, который должен быть отображен в рамке. Если параметр не указан, рамка останется пустой.
NAME - значение этого параметра определяет имя для рамки. Впоследствии по этому имени на рамку можно будет сослаться с помощью параметра TARGET тега <A>.
SCROLLING - показывает, можно ли проматывать содержимое документа в рамке. Может принимать следующие значения:
YES - содержимое рамки МОЖЕТ проматываться.
NO - содержимое рамки НЕ может проматываться.
AUTO - браузер решает, отображать линейку прокрутки или нет (исходя из длины документа). Это значение иcпользуется по умолчанию.
NORESIZE - если этот параметр указан, пользователь не сможет изменить размеры рамки. По умолчанию пользователь МОЖЕТ изменять размеры отображаемых рамок (например, таская границу рамки указательным устройством).
MARGINWIPH - указывает на величину горизонтального отступа внутри рамки.
MARGINHEIGHT - указывает на величину вертикального отступа внутри рамки.
Пример:
<FRAME SRC="file1.html" NAME="myframe1" SCROLLING=NO\ MARGINWIDTH=5>дает рамке имя myframe1 и отображает в ней файл file1.html, причем линейка прокрутки не отображается, ширина горизонтального отступа устанавливается в 5 точек, и пользователь может свободно менять размеры рамки.
Более полный пример:
<FRAMESET ROWS="50%,50%"> <FRAMESET COLS="150,*,150"> <FRAME SRC="frame1.html" NAME="Frame1"> <FRAME SRC="frame2.html" NAME="Frame2"> <FRAME SRC="frame3.html" NAME="Frame3"> </FRAMESET> <FRAMESET COLS="50%,50%"> <FRAME SRC="frame4.html" NAME="Frame4"> <FRAME SRC="frame5.html" NAME="Frame5"> </FRAMESET> </FRAMESET>соответствует примерно следующей раскладке рамок в области отображения:
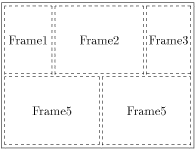
Рис. 2.2.2: Вот так будут располагаться рамки из примера
Что же происходит, если браузер не понимает рамок?
Пользователь видит абсолютно чистый экран и не может добраться до нужной
ему информации.
Как сделать так, чтобы такая ситуация не возникала?
Разработчики расширений предусмотрели такую ситуацию и придумали тег,
содержимое которого никогда не отображается в браузере, понимающем рамки,
тогда как ``глупый'' браузер, увидя незнакомый тег, честно отобразит его
содержимое без применения каких-либо хитростей.
Такой тег называется
<NOFRAMES>
Внутри него рекомендуется
располагать ссылки на документы, не содержащие рамок.
Для организации связей между рамками разработчики предусмотрели параметр TARGET для тега <A>. Он также может применяться в тегах <BASE>, <AREA> и <FORM>.
Евгений Фаддеенков
3.1 Введение
3.2Общая часть
3.2.1 Назначение WWW - сервера. Общая схема работы. Определение
3.2.2Непосредственные функции сервера. Базовые определения
3.2.3Протокол MIME
3.2.4 Протокол HTTP
3.2.5Интерфейс CGI
3.3Сервер NCSA
3.3.1 Требования к ресурсам
3.3.2 Состав дистрибутива сервера NCSA. Варианты дистрибуции
3.3.3Процедура установки сервера NCSA
3.3.4 Конфигурационные файлы. Режимы работы сервера
3.3.5 Выполнение основных операций администрирования
3.3.5.1 Контроль работоспособности сервера
3.3.5.2 Обработка журналов
3.3.5.3Управление доступом
3.3.6 Поддержка русскоязычных кодировок
Широкие возможности WWW - технологии по представлению пользователям
Internet информации, включая текст, картинки, графики, видео и звуковые дорожки,
обусловили процесс бурного роста сети WWW - серверов и Internet
в целом. Целью данного пособия является освещение технологии работы
и процессов установки и администрирования WWW - сервера, т.е.
той части сети, которая отвечает за предоставление гипертекстовой
информации по запросам пользователей сети.
WWW сервер - это такая часть глобальной или внутрикорпоративной сети, которая дает возможность пользователям сети получать доступ к гипертекстовым документам, расположенным на данном сервере. Для взаимодействия с WWW сервером пользователь сети должен использовать специализированное программное обеспечение - броузер (от англ. browser), другое название - программа просмотра.
Рассмотрим более подробно, чем в предыдущих главах, схему работы WWW-сервера. В общем виде она выглядит так:


В первом и третьем случае происходит обращение за новым документом.
Как было описано в главе 2, адрес документа указывается в виде специальной строки, называемой URL. Для протокола HTTP, используемого при взаимодействии WWW клиента и WWW сервера, URL состоит из следующих компонент:
Например:
http://www.cnit.nsu.ru:80/welcome.html
Здесь http означает протокол работы с WWW - сервером
Из общей схемы работы видно, что функции WWW сервера заключаются в следующем:
В общем случае, WWW - сервером будем называть программно - аппаратный комплекс, предназначенный для выполнения вышеперечисленных действий.
В настоящее время все известные WWW - серверы представляют собой компьютер общего назначения с многозадачной операционной системой. Один или несколько процессов такой системы отвечают за поддержку специфических для WWW - сервера функций. Другие процессы ОС отвечают за обеспечение других функций, не обязательно связанных с поддержкой технологии WWW (см. рис. 3-3).

Такая структура приводит к тому, что под WWW сервером начинают подразумевать только часть программного обеспечения, единственными функциями которой являются функции WWW сервера, а остальную часть - компьютер, операционную систему, другие процессы, сетевую структуру называют средой работы WWW сервера или платформой. Ниже приведена таблица 3-1, содержащая список наиболее распространенных платформ для WWW - сервера.
Таблица 3-1
| IBM PC |
|
| Sun SparcStation и SparcServer |
|
| Silicon Graphics
серверы и рабочие станции | IRIS |
В простейшем случае гипертекстовый документ представляет собой совокупность файлов. Представление этих файлов как единого документа производится броузером. По каждому файлу документа броузер делает запрос к WWW - серверу. Таким образом, сервер не имеет представления о структуре и составе документов, он отвечает только за выдачу локальных файлов по запросам.
На различных платформах, в различных операционных системах пути файлов выглядят по разному.
Например:
D:\DOCUMENTS\HTML\INDEX.HTM - в Windows,
/u/data/www/html/index.html - в Unix - системах,
USR:WWW/HTML - в NetWare и т.д.
Путь файла, указываемый в URL, имеет стандартный вид:
/<имя_каталога>/ ... /<имя_каталога>/<имя_файла>
Таким образом, в функции WWW - сервера входит преобразование адреса
из внешнего единого формата в платформенно ориентированный внутренний
формат. Появляется ряд понятий,
специфичных для такого преобразования, необходимых для него.
Это каталог реальной файловой системы сервера, от которого идет вычисление пути, указанного в URL.
Например, если исходным каталогом документов является D:\Documents\HTML\, то на запрос к этому серверу документа по URL
http://<имя_сервера>/index.htm
будет возвращен файл
D:\Documents\HTML\index.html
В случае, когда необходимо осуществить обращение к конкретному каталогу или файлу, находящемуся вне иерархии Исходного каталога документов, используется механизм синонимов. Синоним позволяет явно определить соответствие между путем, указанным в URL, и путем локальной файловой системы.
Например:
Синонимом для /Harvest объявляется /projects/www/harvest
или
синонимом для /test/myfile.html объявляется C:\MYDIR\FILE.HTM
В первом случае все обращения к файлам каталога /Harvest будут обрабатываться в каталоге /projects/www/harvest. Второй пример показывает работу синонима с конкретным файлом файловой системы.
Для каждого сервера определено имя так называемого индексного файла. Обычно этот файл содержит ссылки на другие файлы данного каталога. Содержимое индексного файла выдается сервером в случае, если в URL указан каталог без конкретного файла.
Для многопользовательских операционных систем (таких как Unix) ПО WWW - сервера позволяет каждому пользователю предоставлять доступ к своему собственному набору гипертекстовых документов вне основной иерархии (Исходного каталога документов, Синонимов и т.д.). Этот набор документов должен находиться в собственном (т.н. "домашнем") каталоге пользователя. Для доступа к таким документам в URL перед путем ставится знак тильда и имя пользователя: ~<имя_пользователя>.
Например:
На сервере Indy.cnit.nsu.ru создан пользователь
с именем fancy и "домашним" каталогом /home/fancy.
Собственные гипертекстовые документы он хранит в каталоге /home/fancy/public_html.
При обращении по URL http://Indy.cnit.nsu.ru/~fancy/start.html,
WWW - сервер будет искать документ start.html в
каталоге /home/fancy/public_html.
Протокол MIME - многоцелевое расширение электронной почты, был создан как способ передачи нетекстовой информации: изображений, звука, видео в письмах электронной почты. Механизм оказался удачным, и его перенесли и в on-line сервисы, в том числе WWW. Здесь MIME используется для передачи документов от сервера к клиенту.
В общем виде MIME основывается на передаче вместе с основными данными дополнительной информации, описывающей что это и в каком виде передается. Эта дополнительная информация называется заголовок MIME. Базовой частью заголовка является строка, описывающая тип передаваемого сообщения. Формат строки:
Content-Type: <тип_MIME>
Перечень типов MIME (т.е. видов передаваемых данных) постоянно пополняется и может быть дополнен даже пользователем для описания своего собственного вида данных. Формат типа MIME:
<Тип> / <Подтип> [ ;
<параметры> ]
Где <Тип> - определяет общий тип данных:
Audio - для звуковых данных
Application - данные, являющиеся входными для какого-либо приложения
(программы)
Image - для графических образов
Message - для сообщения, которое само по себе является MIME -
документом
Multipart - для сообщения, состоящего из нескольких MIME - документов
Text - для текстовых данных в различном виде
Video - для видеоданных.
<Подтип> - указывает на специфический формат данных типа
<Тип>
Например:
text/html - текстовые данные в формате HTML
image/giff - графические данные в формате gifF
<Параметры> - список параметров, необходимых для интерпретации
данных.
Для ведения специфичной обработки файлов различных типов и форматов на клиентской и серверной частях поддерживаются списки соответствий типов MIME и расширений файлов. Формат записи такого списка:
<Тип>/<Подтип> <расширение1> ... <расширениеN>
Эти списки сопоставляют всем файлам, имеющим определенные расширения, определенные типы MIME.
Например:
image/giff gif giff
text/html html htm
В первой строке всем файлам с расширением gif и giff приписывается
тип содержимого image/giff. Если для типа содержимого image/giff
определены специальные правила обработки (например,
отображение на экране в определенной области), то так будут обрабатываться
все файлы с расширениями gif и giff.
Протокол HTTP определяет язык запросов от WWW - клиента к WWW - серверу. Сам запрос состоит из следующих компонент:
<Заголовок>
<Метод> <Источник / Данные>
где
Заголовок - определяет версию
протокола HTTP и другие служебные параметры;
Метод - одно из ключевых слов:
GET - для передачи запросов на выдачу документов
PUT, POST - для передачи данных от клиента к серверу
(например, из форм)
Пример запроса:
HTTP/1.1
GET /index.html
Описывает запрос на получение файла index.html из корневого каталога документов сервера.
Помимо доступа к статическим документам сервера существует возможность получения документов как результата выполнения прикладной программы. Такая возможность реализуется на сервере WWW благодаря использованию интерфейса CGI (Common Gateway Interface). Спецификация CGI описывает формат и правила обмена данными между ПО WWW сервера и запускаемой программой.
Для инициирования CGI необходимо, чтобы в запрашиваемом URL был указан путь до запускаемой программы. ПО WWW сервера исполняет эту программу, передает ей входные параметры и возвращает результаты ее работы, как результат обработки запроса, клиенту. CGI - программой может являться любая программа локальной операционной системы сервера - в двоичном виде или в виде программы для интерпретатора (Basic, SH, Perl и т.д.).
С целью облегчения администрирования CGI - программ, а также для удовлетворения требованиям безопасности CGI - программы группируются в одном или нескольких явно указанных серверу каталогах. По умолчанию это каталог cgi-bin в иерархии серверных каталогов, однако, его имя и положение могут отличаться.
Например:
клиент, обращающийся к CGI - программе test-query, будет использовать
URL http://<имя_сервера>/cgi-bin/test-query
Интерфейс CGI позволяет расширить границы применения WWW - технологии. CGI - программа может обрабатывать сигналы с датчиков установок, взаимодействовать с мощным сервером баз данных, переводить и т.п. Полное описание интерфейса и требований к приложениям, использующих его, приведены в главе 4 настоящего отчета.
Национальный Центр по Суперкомпьютерным Приложениям (NCSA) Иллинойского
университета стал второй организацией после ЦЕРН, интенсивно взявшейся
за развитие WWW - технологии. Семейство ПО WWW - серверов NCSA
прошло длинный путь развития. Последние версии поддерживают все
современные возможности, включая виртуальные узлы, управление
доступом, параллельную обработку запросов и т.п.
Программное обеспечение сервера NCSA представляет собой прикладное программное обеспечение, предназначенное для работы под ОС Unix. В зависимости от аппаратной платформы требуемый размер оперативной памяти и дискового пространства существенно изменяются. Для семейства "Unix для PC" (Solaris, SCO, UnixWare, Linux, BSD, BSDI), необходимо ориентироваться на 2 Mb оперативной памяти. Дисковое пространство, требуемое при установке, составляет около 2Mb, однако при планировании установки нужно учитывать, что при интенсивном доступе к серверу статистика доступа будет составлять до нескольких сот килобайт в день и нескольких десятков мегабайт в месяц.
Сервер NCSA поставляется как в виде исходных текстов, так и в виде исполняемых модулей для различных операционных систем. Распакованный дистрибутив размещается в каталоге httpd_<номер версии>-<модификация> где <номер версии> - версия программного обеспечения WWW сервера, <модификация> - модификация текущей версии.
Например:
httpd_1.5.1-export
В этом каталоге содержатся следующие файлы и подкаталоги:
README - текстовый файл для первоначального ознакомления. Содержит список всех значимых файлов и каталогов с объяснением их назначения.
COPYRIGHT - текстовый файл с описанием лицензионного соглашения на использование ПО WWW - сервера NCSA.
CHANGES - текстовый файл со списком изменений между различными версиями ПО сервера.
Makefile - файл верхнего уровня для утилиты make. Содержит список команд, которые необходимо выполнить для сборки и установки ПО WWW - сервера.
src - каталог с исходными текстами ПО сервера.
conf - каталог, содержащий примеры конфигурационных файлов ПО сервера.
icons - каталог, содержащий иконки, необходимые для работы сервера.
cgi-bin - каталог, содержащий примеры CGI - программ.
cgi-src - каталог, содержащий исходные тексты примеров CGI - программ.
support - каталог с программным обеспечением, не
являющимся часью ПО сервера, но полезным при работе с ним.
Для запуска процедуры сборки и установки сервера необходимо в корневом каталоге сервера, описанном в предыдущем параграфе, запустить утилиту make. Для сборки сервера необходимо указать команде make аббревиатуру операционной системы:
aix3, aix4, sunos, sgi4, sgi5, hp-cc, hp-gcc, solaris, netbsd, svr4, linux, next, ultrix, osf1, aux, bsdi. Полный список поддерживаемых систем можно получить, выполнив команду make без параметров. Каждая аббревиатура ассоциирована с конкретной операционной системой. Появление дополнительных параметров после дефиса указывает на специфику конкретной конфигурации в одной и той же ОС. Например, hp-cc и hp-gcc указывают на общий тип ОС - HP-UX, однако ориентированы на использование разных компиляторов - базового C - компилятора (cc) или GNU C (gcc). Для сборки сервера под ОС UnixWare необходимо использовать команду make svr4.
Ряд основных параметров сервера - пути файлов, режимы работы задаются по умолчанию на этапе сборки. В случае, если нужна их корректировка под конкретные условия, необходимо отредактировать файл src/config.h.
После сборки сервера необходимо разместить его компоненты в файловой системе. Исполняемый модуль сервера httpd размещается в каталоге серверных программ - /usr/local/sbin или /usr/sbin. Файлы конфигурации, журналы и стандартные cgi-программы размещаются в подкаталогах каталога, определяемого параметром ServerRoot. Обычно это /usr/local/etc/httpd, однако его можно изменить либо изменив параметр HTTPD_ROOT файла src/config.h, либо указав ключ -d при запуске сервера.
Например:
/usr/local/sbin/httpd -d /var/httpd
В каталоге, определяемом параметром ServerRoot, размещаются три подкаталога:
Главный файл конфигурации (ГКФ) сервера содержит все параметры, необходимые серверу для начала работы, а также пути других конфигурационных файлов. По умолчанию, главный файл конфигурации сервера находится в подкаталоге conf/ каталога и имеет имя httpd.conf. При запуске серверу можно указать другой путь, используя ключ -f.
Например:
/usr/local/sbin/httpd -f /etc/httpd.config
Ниже приведены параметры, указываемые в главном файле конфигурации
сервера, с необходимыми пояснениями. Значения параметров отделяются
от названия одним или несколькими пробелами или табуляциями. Если
одному параметру соответствуют несколько значений, они разделяются
запятыми.
Параметры запуска серверных процессов
Определяет способ запуска сервера:
ServerType inetd серверный процесс запускается в ответ на каждое обращение клиента через механизм inetd. После обработки запроса, сервер прекращает свою работу.
ServerType standalone серверный процесс запускается один раз и находится в состоянии ожидания запросов клиентов. После обработки запроса, сервер остается запущенным.
Определяет порт tcp, по которому сервер принимает запросы клиентов. Этот параметр используется только для сервера типа standalone. При механизме старта inetd порт определяется конфигурационным файлом сервера inetd - inetd.conf. Стандартный порт для WWW - сервера - 80.
Пример:
Port 80
Для режима standalone определяют количество процессов сервера при многопоточной обработке. StartServers - указывает число процессов сервера, создаваемых при запуске httpd. MaxServers определяет максимальное число одновременно работающих процессов сервера.
Пример:
StartServers 3
MaxServers 5
Определяет время (в секундах), которое серверный процесс, запущенный в режиме standalone, будет ожидать повторного обращения клиента. По умолчанию используется 1200 секунд.
Пример:
TimeOut 3600
Определяют имя пользователя и группу, права которого получает сервер при запуске в режиме standalone. Изменение прав сервера производится с целью предотвращения доступа WWW - клиентов к файлам операционной системы, не являющимися общедоступными. Например:
User nobody
Group nobody
Информационные параметры для WWW - клиентов
Определяет имя сервера, которое пересылается клиенту вместе с другими параметрами запроса. Используется в случае, если сервер имеет несколько имен (синонимов).
Например:
ServerName Indy.cnit.nsu.ru
Определяет адрес электронной почты администратора сервера. При возникновении каких - либо ошибок в работе сервера, он выдает клиенту сообщение с просьбой проинформировать о них администратора сервера по указанному Email.
Например:
ServerAdmin fancy@nsu.ru
Расположение необходимых файлов и каталогов
Определяет местоположение каталога ServerRoot. По умолчанию, это /usr/local/etc/httpd или измененное значение параметра HTTPD_ROOT файла src/config.h.
Например:
ServerRoot /var/httpd
Определяет местоположение файла - журнала ошибок, в который заносятся все сообщения об ошибках, возникающих в процессе работы сервера. Если значение не начинается со slash (/), подразумевается путь относительно ServerRoot.
Например:
ErrorLog logs/errlog
Журналом ошибок является файл /var/httpd/logs/errlog
Определяет местоположение файла - журнала доступа, в который заносятся данные обо всех передачах данных между WWW - клиентом и WWW - сервером. Если значение не начинается со slash (/), подразумевается путь относительно ServerRoot.
Например:
TransferLog logs/translog
Журналом доступа является файл /var/httpd/logs/translog
Определяет местоположение файла - журнала клиентов, в который заносятся данные о программном обеспечении, используемом WWW клиентами при доступе к данному серверу. Если значение не начинается со slash (/), подразумевается путь относительно ServerRoot.
Например:
TransferLog logs/agentlog
Журналом клиентского программного обеспечения является файл /var/httpd/logs/agentlog
Определяет местоположение файла в который записываются все факты обращений к данным сервера в виде ссылок от клиентов к данным. Если значение не начинается со slash (/), подразумевается путь относительно ServerRoot.
Например:
RefererLog logs/reflog
Журналом ссылок является файл /var/httpd/logs/reflog
Определяет местоположение файла, хранящего номер процесса запущенного WWW - сервера. Используется для остановки работы сервера путем посылки сигнала командой kill. Если значение не начинается со slash (/), подразумевается путь относительно ServerRoot.
Например:
PidFile logs/httpd.pid
Номер процесса - сервера записывается при старте в файл /var/httpd/logs/httpd.pid
Определяет местоположение файла управления доступом. Если значение не начинается со slash (/), подразумевается путь относительно ServerRoot.
Например:
AccessConfig conf/access.conf
Определяет местоположение файла, содержащего список соответствий расширений файлов ОС типам MIME. По умолчанию используется файл conf/mime.types в каталоге, определяемом ServerRoot. Если не начинается с backslash (/), подразумевается путь относительно ServerRoot.
Например:
TypesConfig /etc/mime.types
Определяет местоположение каталога, в который записывается файл дампа памяти при возникновении сбоя.
Например:
CoreDirectory /tmp
Параметры протоколирования
Определяет, будут ли несколько протоколов записываться в один файл (Combined) или каждый будет записан в свой файл (Separate).
Например:
LogOptions Separate
Определяет имена серверов, обращения от которых не будут протоколироваться.
Например:
RefererIgnore Indy.cnit.nsu.ru
Другие режимы работы
Определяет интенсивность обращений WWW сервера к серверу имен Интернет. Minimum означает, что сервер будет обращаться к DNS только при необходимости проверить ограничения доступа по домену. Standard означает, что сервер будет обращаться к серверу имен каждый раз при обработке запроса клиента. Maximum означает, что сервер будет дважды обращаться к серверу имен при каждой обработке запроса.
Например:
DNSMode Standard
Процедура определения конфигурации сервера
После запуска основного серверного процесса сервер пытается открыть главный конфигурационный файл. Этот файл ищется по умолчанию в каталоге /usr/local/etc/http/conf с именем httpd.conf. Умолчание можно изменить при сборке системы редактированием файла src/config.h. За каталог отвечает параметр HTTPD_ROOT, за имя файла - параметр SERVER_CONFIG_FILE. Изменить значения по умолчанию можно при запуске сервера, указав ключи -h и-f (см. выше).
Местоположение файлов конфигурации доступа, документов, типов
MIME, а также файлов журналов сервер получает из главного конфигурационного
файла. Если каких - либо параметров там нет, их значения берутся
по умолчанию (см. src/config.h).
Конфигурация ресурсов
Расположение файлов данных, их интерпретация сервером и поведение
сервера при обращении к разным типам файлов определяются параметрами
файла конфигурации ресурсов. Ниже приведен список основных параметров
с пояснениями.
Определяет каталог локальной файловой системы, от которого начинается отсчет виртуального пути URL.
Например:
DocumentRoot /apply/www
Определяет название публичного подкаталога пользователей. ПО WWW - сервера позволяет обеспечить внешний доступ к гипертекстовым документам пользователей базовой операционной системы. Для этого пользователям необходимо создать в своем домашнем каталоге подкаталог с именем, определяемым параметром UserDir. После этого все обращения по URL:
http://<имя_сервера>/~<имя_пользователя_ОС>
будут транслироваться в реальный путь до подкаталога, определенного параметром UserDir в домашнем каталоге пользователя <имя_пользователя_ОС>.
Например:
UserDir public_html
при этом при обращении по URL
http://www.nsu.ru/~fancy/index.html
сервер будет искать файл Index.html в подкаталоге
public_html/ домашнего каталога пользователя fancy.
Переадресует запрос к одной иерархии в запрос к другой иерархии, возможно расположенной на другом сервере.
Например:
Redirect /HTTPd/ http://hoohoo.ncsa.uiuc.edu/
Определяет синоним для документа или каталога на локальном сервере.
Пример:
Alias /icons /var/opt/images
Определяет синоним для каталогов, содержащих CGI - программы.
Пример:
ScriptAlias /hrv-cgi /var/opt/cgi
Определяет имена файлов, трактующихся сервером как индексные. Их содержимое выдается сервером при обращении к данному каталогу.
Пример:
DirectoryIndex index.html index.html index.cgi
Определяет имя файла, трактующегося сервером как файл управления доступом (см. раздел об управлении доступом).
Пример:
AccessFileName .htaccess
Проверка работоспособности сервера может осуществляться различными способами. На Unix - платформе, в режиме standalone, можно посмотреть список процессов, выделив среди них процессы с именем httpd:
#
ps -aef | grep httpd
root
28816 1 0 Nov 14 ? 7:42 /usr/local/sbin/httpd
nobody 28817 28816 0 Nov
14 ? 5:50 /usr/local/sbin/httpd
nobody 28818 28816 0 Nov
14 ? 5:32 /usr/local/sbin/httpd
nobody 28819 28816 0 Nov
14 ? 4:49 /usr/local/sbin/httpd
nobody 28820 28816 0 Nov
14 ? 5:24 /usr/local/sbin/httpd
nobody 28821 28816 0 Nov
14 ? 5:42 /usr/local/sbin/httpd
root 19150 19145 0 14:57:58
pts/4 0:00 grep httpd
#
Мы увидим несколько процессов, у одного из которых собственником является root, а у других - пользователь, определенный параметром User главного конфигурационного файла (ГКФ). Процесс с собственником root запускается первым. Он контролирует работу остальных процессов - серверов. По использованному процессорному времени (колонка 8 примера) можно судить о загруженности серверов.
Если сервер работает в режиме inetd или необходимо проверить работоспособность сервера извне, нужно выполнить команду telnet, указав ей имя машины - сервера и номер порта. После установления соединения наберите команду GET /. Сервер должен выдать содержимое корневого каталога документов или индексного файла, находящегося в этом каталоге. Номер порта обычно равен 80. В режиме standalone он определяется параметром Port ГКФ. Для режима inetd он определяется парой файлов - services и inetd.conf, определяющих соответствие между входными tcp - портами и сервисами Unix.
Например:
$ telnet www.cnit.nsu.ru
80
Trying 193.124.209.70...
Connected to Indy.
Escape character is '^]'.
GET /
<HTML>
<HEAD>
<TITLE>Novosibirsk Center
of New Information Technologies</TITLE>
</HEAD>
<BODY
. . .
</BODY>
</HTML>
Connection closed by foreign host.
$
Время от времени возникает необходимость уменьшить размер файлов
статистики путем их удаления или переноса в другое место. Если
сервер находится в режиме inetd, можно свободно удалять и переносить
файлы статистики. Они снова создадутся по указанным в ГКФ путям.
Если же сервер работает в режиме standalone, эти файлы постоянно
открыты процессами - серверами. Удаление или перенос их не освободят
место на диске и не приведут к созданию новых файлов. Для корректной
работы с журналами в этом случае, необходима остановка работы
сервера. Необходимо "убить" процессы - серверы, перенести
файлы журналов и перезапустить сервер. "Убить" процессы
- серверы можно послав команду kill процессу с номером, указанном
в файле PidFile (см. параметры ГКФ). Пример последовательности
команд для выполнения такой операции:
kill `cat /usr/local/etc/httpd/logs/httpd.pid`
mv /usr/local/etc/httpd/logs/*.log
/otherdir
/usr/local/sbin/httpd
Для анализа файлов статистики существует большое количество программного обеспечения, делающего "вытяжку" из них в виде диаграмм, сравнительных таблиц и т.д.
Сервер NCSA содержит гибкие средства управления доступом. С их
помощью можно централизованно или децентрализованно управлять
доступом, основываясь на структуре адреса WWW - клиента, создавать
пары имя/пароль для документов или целых подразделов, создавать
несколько пар имя/пароль.
Управление доступом с использованием пар имя/пароль
Для введения ограничений на доступ ко всем документам определенного каталога необходимо создать в этом каталоге файл управления доступом. Этот файл имеет фиксированное имя, определяемое параметром AccessFileName файла конфигурации доступа. По умолчанию, это файл .htaccess.
Пример содержимого файла .htaccess
AuthUserFile /otherdir/.htpasswd
AuthGroupFile /dev/null
AuthName ByPassword
AuthType Basic
<Limit GET>
require user pumpkin
</Limit>
AuthUserFile указывает путь файла паролей, который должен находиться вне данного каталога.
Limit GET ограничивает доступ по методу GET, предоставляя его только пользователю pumpkin. Для ограничения других методов доступа (например, в каталогах CGI) используется перечисление всех методов:
<Limit GET POST PUT>
require user pumpkin
</Limit>
Для создания файла паролей необходимо воспользоваться утилитой htpasswd, входящей в состав дистрибутива сервера:
htpasswd -c /otherdir/.htpasswd
pumpkin
После запуска она дважды запросит пароль для пользователя pumpkin и создаст файл паролей /otherdir/.htpasswd.
Использование нескольких пар имя/пароль
Использование нескольких пар имя/пароль достигается путем описания группы, в которую входят несколько пользователей, и указания имени группы в операторе Limit.
htpasswd /otherdir/.htpasswd
peanuts
htpasswd /otherdir/.htpasswd
almonds
htpasswd /otherdir/.htpasswd
walnuts
my-users: pumpkin peanuts almonds walnuts
где my-users - имя группы,
pumpkin, peanuts, almonds, walnuts - список пользователей, входящих в группу.
AuthUserFile /otherdir/.htpasswd
AuthGroupFile /otherdir/.htgroup
AuthName ByPassword
AuthType Basic
<Limit GET>
require group my-users
</Limit>
Все документы данного каталога будут доступны всем членам группы my-users после проведения процедуры аутентификации (ввода пароля).
Ограничение доступа по сетевому имени
В этом случае управление доступом осуществляется на основе сравнения сетевого имени машины - клиента с заранее заданным образцом. Если выявится совпадение, начинают действовать специальные правила доступа.
Пример ограничения доступа на чтение. Чтение разрешено всем пользователям машин домена cnit.nsu.ru:
Содержимое файла .htaccess:
AuthUserFile /dev/null
AuthGroupFile /dev/null
AuthName ExampleAllowFromCNIT
AuthType Basic
<Limit GET>
order deny, allow
deny from all
allow from .cnit.nsu.ru
</Limit>
Оператор order указывает порядок определения требований к доступу:
сначала ограничения, затем разрешения.
deny from all - сначала запрещает доступ для всех,
allow from .cnit.nsu.ru - затем разрешает доступ для машин домена cnit.nsu.ru.
Оператор AuthName задает имя данного ограничения доступа - произвольную комбинацию букв и цифр.
Пример запрета на доступ для всех машин домена nstu.nsk.su:
Содержимое файла .htaccess:
AuthUserFile /dev/null
AuthGroupFile /dev/null
AuthName ExampleAllowFromCNIT
AuthType Basic
<Limit GET>
order allow, deny
deny from .nstu.nsk.su
allow from all
</Limit>
Исторически сложилось, что в России распространены несколько русскоязычных кодировок, в основном ориентированных на разные платформы. Наиболее известные из них:
Специалисты утверждают что всего в России имеют хождение 11 кодировок русского алфавита.
Если Ваш WWW сервер ориентирован на использование внутри организации или его пользователями будет являться ограниченный круг людей с однотипными рабочими местами, Вы можете ограничиться одной кодировкой русскоязычной информации на сервере.
Сложности возникают, когда Вы захотите расширить круг клиентов сервера. Вам необходимо будет организовать поддержку нескольких кодовых страниц для русскоязычных документов. Приведенный выше список из четырех кодировок удовлетворит более 99% всех возможных абонентов сервера.
Вообще говоря, в составе языка HTML имеются теги, определяющие кодировку документа и должные позволить корректно прочитать документ в любой кодировке. Однако в связи с тем, что эти теги не поддерживаются ни одним из известных броузеров, надеяться на них не стоит. Возможно, в будущем эта ситуация изменится, и проблема с кодировками будет решена.
Для поддержки нескольких кодовых страниц применяется множество методов, которые можно разбить на две группы:
В первом случае, на сервере физически присутствуют все файлы во всех поддерживаемых кодировках. Документы в различных кодировках отличаются между собой по правилам образования путей и имен.
Например:
indexw.html,
indexa.html
- добавление суффиксов, определяющих
кодировку. Или
.../koi8/index.html, .../win/index.html - различные базовые каталоги для разных кодировок.
При этом выделяется одна мастер - кодировка, в которой новые документы располагаются на сервере, а все остальные варианты документов получаются после работы специальной программы - перекодировщика. Программа - перекодировщик может запускаться вручную - администратором WWW сервера или автоматически, с использованием команд cron, at.
Во втором случае, доступ к документам осуществляется через дополнительную программу - перекодировщик, динамически перекодирующую документы сервера в кодировку WWW - клиента. Эта программа может быть CGI - программой, через которую всегда осуществляется доступ к русскоязычной части сервера. На вход такой программе передается реальный путь документа и кодировка WWW - клиента, в которую нужно перекодировать указанный документ (см. рис. 12.1)

Программа - перекодировщик может также располагаться между WWW - клиентом и сервером (см.рис.12.2). В таком варианте она называется PROXY.

Однако здесь возникает проблема с перекодировкой всех данных, включая графику, видео, аудио и других нетекстовых материалов. Для ее решения PROXY придается дополнительный интеллект - определять тип передаваемых данных по заголовку MIME и решать, перекодировать документ или нет, на основе его типа. Программы - перекодировщики с различными кодировками обрабатывают обращения к разным портам tcp сервера. Клиенту работа с PROXY видна в URL.
Например:
http://www.nsu.ru:80/index.html
- для кодировки КОИ-8,
http://www.nsu.ru:8000/index.html
- для кодировки ISO-8859-5
и т.д.
4.1 WWW (World Wide Web) и средства интерактивного взаимодействия
4.2Спецификация CGI
4.2.1Переменные окружения
4.2.2Стандартный вывод
4.2.3Стандартный входной поток
4.2.4Аргументы командной строки
4.3Последовательность действий для обработки входных данных cgi-модуля для разных методов запроса GET и POST
4.3.1Для метода GET
4.3.2Для метода POST
Приложение 1: Конструкции языка HTML для построения форм
При написании данной главы использовались материалы National Center for Supercomputing Applications
Цель данной главы познакомить пользователя с той частью WWW-технологий которая связана с созданием интерактивных интерфейсов и предполагается что пользователь знаком с основами WWW, HTML и С/С++.
В общем случае, интерактивный интерфейс пользователя представляет собой систему, обеспечивающую взаимодействие пользователя и программы. Для WWW, интерактивный интерфейс можно определить как последовательность HTML-документов, реализующих интерфейс пользователя. Можно также условно классифицировать принципы построения интерфейса по типу формирования HTML-документа:
В первом случае источником интерфейса является HTML-документ, созданный в каком-либо текстовом или HTML-ориентированном редакторе. Следовательно, данный документ остается неизменным в течение использования. Во втором случае источником интерфейса является HTML-документ сгенерированный cgi-модулем. Следовательно, появляется некоторая гибкость в видоизменении интерфейса во время использования.
Таким образом, можно ввести понятие интерактивного интерфейса для WWW.
Интерактивный интерфейс для WWW представляет собой последовательность статических или динамически формируемых HTML-документов, реализующих интерфейс пользователя.
Практически любая задача, решающая проблему получения данных от клиента, связана с построением интерфейса. Наиболее интересным является построение интерфейсов к различным базам данных, доступ к SQL-серверу, получение информации от периферийных устройств, создание клиентских рабочих мест. Все это возможно посредством CGI(Common Gateway Interface).
Common Gateway Interface (CGI) является стандартом интерфейса внешней прикладной программы с WWW сервером.
Задача построения вышеназванных интерфейсов делится на две части:
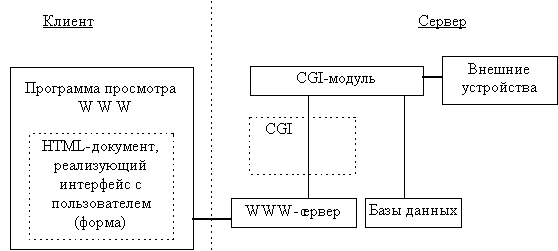
Для создания клиентской части необходимо создать HTML-документ, в котором реализован интерфейс с пользователем. В языке HTML это возможно посредством форм.
Конструкции языка HTML, используемые при реализации форм, даны в приложении 1 к гл. 4.
Серверная часть состоит из исполняемого модуля, решающего основные задачи обработки данных поступающих от клиентской части, формирования ответа в формате HTML, и т.д. Такой модуль называется cgi-модулем.
Для реализации взаимодействия "клиент-сервер" важно, какой метод HTTP запроса использует клиентская часть при обращении к WWW серверу. В общем случае, запрос - это сообщение, посылаемое клиентом серверу. Первая строка HTTP запроса(см. гл.3) включает в себя метод, который должен быть применен к запрашиваемому ресурсу, идентификатор ресурса(URI-Uniform Resource Identifier), и используемую версию HTTP-протокола. В рассматриваемом нами случае, клиентская часть применяет методы запроса POST и GET. Метод POST используется для запроса серверу, чтобы тот принял информацию, включенную в запрос, как относящуюся к ресурсу, указанному идентификатором ресурса. Метод GET используется для получения любой информации, идентифицированной идентификатором ресурса в HTTP запросе.
Для WWW-сервера стандарта NCSA прикладные программы или CGI-модули, обрабатывающие поток данных от клиента или (и) формирующие обратный поток данных могут быть написаны на таких языках программирования как:
CGI определяет 4 информационных потока.
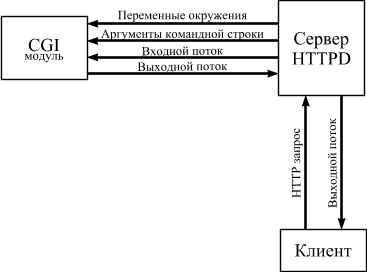
Рисунок 4-2. CGI-интерфейс.
Переменные окружения условно делятся на два типа:
К переменным первого типа относятся следующие переменные:
SERVER_SOFTWARE содержит информацию о WWW сервере (название/версия)
SERVER_NAME содержит информацию об имени машины, на которой запущен WWW сервер, символическое имя или IP адрес соответствующие URL.
GATEWAY_INERFACE содержит информацию о версии CGI(CGI/версия)
Следующие переменные являются специфичными для разных типов запросов и значения этим переменным присваиваются перед вызовом cgi-модуля.
CONTENT_LENGTH значение этой переменной соответствует длине стандартного входного потока в символах.
CONTENT_TYPE эта переменная специфицирована для запросов содержащих дополнительную информацию, таких как HTTP POST и PUT, и содержит тип данных этой информации.
SERVER_PROTOCOL эта переменная содержит информацию об имени и версии информационного протокола (протокол/версия).
SERVER_PORT значение переменной содержит номер порта, на который был послан запрос.
REQUEST_METHOD метод запроса, который был использован "POST","GET","HEAD" и т.д.
PATH_INFO значение переменной содержит полученный от клиента виртуальный путь до cgi-модуля
PATH_TRANSLATED значение переменной содержит физический путь до cgi-модуля, преобразованный из значения PATH_INFO.
SCRIPT_NAME виртуальный путь к исполняемому модулю, используемый для получения URL.
QUERY_STRING значение этой переменной соответствует строке символов следующей за знаком "?" в URL соответствующему данному запросу. Эта информация не декодируется сервером.
REMOTE_HOST содержит символическое имя удаленной машины, с которой был произведен запрос. В случае отсутствия данной информации сервер присваивает пустое значение и устанавливает переменную REMOTE_ADDRESS.
REMOTE_ADDRESSсодержит IP адрес клиента
AUTH_TYPE если WWW-сервер поддерживает аутентификацию (подтверждение подлинности) пользователей и cgi-модуль является защищенным от постороннего доступа то, значение переменной специфицирует метод аутотентификации.
REMOTE_USER содержит имя пользователя в случае аутотентификации.
REMOTE_IDENT содержит имя пользователя, полученное от сервера (если сервер поддерживает аутентификацию согласно RFC 931)
HTTP_ACCEPT список типов MIME известных клиенту. Каждый тип в списке должен быть отделен запятой согласно спецификации HTTP (тип/подтип,тип/подтип и т.д.)
HTTP_USER_AGENT название программы просмотра которую использует клиент при посылке запроса.
СGI - модуль выводит информацию в стандартный выходной поток. Этот вывод может представлять собой или документ, сгенерированный cgi-модулем, или инструкцию серверу, где получить необходимый документ. Обычно cgi-модуль производит свой вывод. Преимущество такого подхода в том, что cgi-модуль не должен формировать полный HTTP заголовок на каждый запрос.
Заголовок выходного потока
В некоторых случаях необходимо избегать обработки сервером вывода cgi-модуля, и посылать клиенту данные без изменений. Для отличия таких cgi-модулей, CGI требует, чтобы их имена начинались на nph-. В этом случае
формирование синтаксически правильного ответа клиенту cgi-модуль берет на себя.
Заголовки с синтаксическим разбором
Вывод cgi-модуля должен начинаться
с заголовка содержащего определенные строки и завершаться двумя
символами CR(0x10).
Любые строки не являющиеся директивами сервера, посылаются непосредственно клиенту. На данный момент, CGI спецификация определяет три директивы сервера:
Content-type
MIME или тип возвращаемого документа
Например: Content-type: text/html <CR><CR> сообщает серверу, что следующие за этим сообщением данные - есть документ в формате HTML
Location
указывает серверу, что возвращается не сам документ, а ссылка на него
Если аргументом является URL, то сервер передаст указание клиенту на перенаправление запроса. Если аргумент представляет собой виртуальный путь, сервер вернет клиенту заданный этим путем документ, как если бы клиент запрашивал этот документ непосредственно.
Например: Location: http://host/file.txt приведет к тому, что WWW сервер выдаст file.txt, как если бы он был затребован клиентом. Если cgi-модуль возвращает ссылки на gopher сервер, например на gopher://gopher.ncsa.uiuc.edu/. Вывод будет следующий:
Location: gopher://gopher.ncsa.uiuc.edu/
*Status
задает серверу HTTP/1.0 строку-статус, которая будет послана клиенту в формате: nnn xxxxx
где: nnn - 3-х цифровой код статуса
ххххх - строка причины
Например: HTTP/1.0 200 OK
Server: NCSA/1.0a6
Content-type: text/plain
<динамически генерируемый текст сообщения>
В данном случае, клиенту будет сообщено об успешном выполнении запроса.
В случае метода запроса POST данные передаются как содержимое HTTP запроса. И будут посланы в стандартный входной поток.
Данные передаются cgi-модулю в следующей форме:
На файловый дескриптор стандартного потока ввода посылается CONTENT_LENGTH байт. Так же сервер передает cgi-модулю CONTENT_TYPE (тип данных). Сервер не посылает символ конца файла после передачи CONTENT_LENGTH байт данных или после того, как cgi-модуль их прочитает. Переменные окружения CONTENT_LENGTH и CONTENT_TYPE устанавливаются в тот момент, когда сервер выполняет cgi-модуль. Таким образом, если в результате исполнения формы с аргументом тега FORM - METHOD="POST" сформирована строка данных firm=МММ&price=100023, то сервер установит значение CONTENT_LENGTH равным 21 и CONTENT_TYPE в application/x-www-form-urlencoded, а в стандартный поток ввода посылается блок данных.
В случае метода GET, строка данных передается как часть URL.
Т.е. например
http://host/cgi-bin/script?name1=value1&name2=value2
В этом случае переменная окружения QUERY_STRING принимает значение
name1=value1&name2=value2
СGI-модуль в командной строке от сервера получает:
Ключевые слова, имена и значения полей формы передаются декодированными (из HTTP URL формата кодирования) и перекодированными в соответствии с правилами кодирования Bourne shell так, что cgi-модуль в командной строке получит информацию без необходимости осуществлять дополнительные преобразования.
Исходя из разницы методов запросов GET и POST, можно определить последовательность действий для обработки входных данных cgi-модуля для разных типов запросов.
Очевидно, что отличие только в источнике данных. Поэтому, в принципе, возможно создание единого модуля для методов POST и GET. Необходимо только добавить в начало проверку значения переменной REQUEST_METHOD для определения метода запроса. После формирования структуры "имя-значение" можно приступить к решению задач, ради которых, собственно, создавался cgi-модуль. Понятно, что задачи, решаемые cgi-модулем, могут быть очень разнообразными (получение и обработка почты, доступ к базам данных, гостевая книга и т.д.).
Следующим важным моментом является динамическое формирование cgi-модулем HTML-документа (оформление результата работы модуля). Например, таблицы выборки из базы данных.
Для этого cgi-модуль должен выдать в стандартный выходной поток
заголовок состоящий из строки:
Content-type: text/html и пустой строки (двух символов
CR)
После этого заголовка можно давать любой текст в формате HTML.
В качестве примера рассмотрим работу тестовых программ поставляющихся вместе с программным обеспечением сервера НТТРD стандарта NCSA.
Для тестирования работы форм поставляются программы :
post-query - для тестирования работы форм с методом запроса
POST
query - для тестирования работы форм с методом запроса
GET
util.c - описание функций для обработки входного потока
(используется query и post-query).
Рассмотрим простой пример формы на языке HTML использующую программу query.
<HTML>
<HEAD>
<TITLE>Пример использования CGI</TITLE>
</HEAD>
<BODY>
<FORM ACTION="http://iceman.cnit.nsu.ru/cgi-bin/post-query"
METHOD="POST">
<B>Введите свое имя<I>(Фамилию Имя Отчество)</I>:</B>
<INPUT name=RealName type=text size=40 maxlength=60 value="Петров
Иван Сидорович"><P>
Пол: <INPUT name=Sex type=Radio value="Мужской" CHECKED>-
мужской <INPUT name=Sex type=Radio value="Женский">-женский<P>
<INPUT name=Submit type=submit value="Послать запрос"><BR>
<INPUT name=Reset type=reset value="Сброс">
</FORM>
</BODY>
</HTML>
После инициации формы путем нажатия кнопки "Послать запрос"
WWW сервер обрабатывает поток
данных от формы (заменяет все пробелы в именах и значениях на
символ "+", заменяет все символы с десятичным кодом
большим 128 на символ "%" и следующим за ним шестнадцатеричным
кодом символа (например "И" в %С8)).
Выходной поток примет следующий вид:
RealName=%CF%E5%F2%F0%EE%E2+%C8%E2%E0%ED+%D1%E8%E4%EE%F0
%EE%E2%E8%F7&Sex=%CC%F3%E6%F1%EA%EE%E9&Submit=%CF%EE%F1
%EB%E0%F2%FC+%E7%E0%EF%F0%EE%F1
В момент передачи управления модулю post-query сервер присваивает значения переменным окружения и аргументам командной строки:
argc = 0. argv =
SERVER_SOFTWARE = NCSA/1.5.1
SERVER_NAME = iceman.cnit.nsu.ru
GATEWAY_INTERFACE = CGI/1.1
SERVER_PROTOCOL = HTTP/1.0
SERVER_PORT = 80
REQUEST_METHOD = POST
HTTP_ACCEPT = image/gif, image/x-xbitmap, image/jpeg, image/pjpeg,*/*
PATH_INFO =
PATH_TRANSLATED =
SCRIPT_NAME = /cgi-bin/test-cgi
QUERY_STRING =
REMOTE_HOST = fwa.cnit.nsu.ru
REMOTE_ADDR = 193.124.209.74
REMOTE_USER =
AUTH_TYPE =
CONTENT_TYPE = application/x-www-form-urlencoded
CONTENT_LENGTH = 142
Результат работы post-query:
<H1>Query Results</H1>You submitted the following
name/value pairs:<p>
<ul>
<li> <code>RealName = Петров Иван Сидорович</code>
<li> <code>Sex = Мужской</code>
<li> <code>Submit = Послать запрос </code>
</ul>
И на экране браузера
Query Results
You submitted the following name/value pairs:
RealName = Петров Иван Сидорович
Sex = Мужской
Submit = Послать запрос
Ниже приведен исходный текст программы post-query.
#include <stdio.h>
#ifndef NO_STDLIB_H
#include <stdlib.h>
#elsechar *getenv();
#endif
#define MAX_ENTRIES 10000
typedef struct {
char *name;
char *val;
} entry;
char *makeword(char *line, char
stop);
char *fmakeword(FILE *f, char
stop, int *len);
char x2c(char *what);
void unescape_url(char *url);
void plustospace(char *str);
main(int argc, char *argv[])
{
entry entries[MAX_ENTRIES];
register int x,m=0;
int cl;
printf("Content-type:
text/html%c%c",10,10);
if(strcmp(getenv("REQUEST_METHOD"),"POST"))
{ printf("This
script should be referenced with a METHOD of POST.\n");
printf("If you don't
understand this, see this "); printf("<A HREF=\"http://www.ncsa.uiuc.edu/SDG/Software/Mosaic/Docs/fill-out-forms/overview.html\">
forms overview</A>.%c",10);
exit(1);
} if(strcmp(getenv("CONTENT_TYPE"),"application/x-www-form-urlencoded"))
{printf("This script
can only be used to decode form results. \n");
exit(1);
}
cl = atoi(getenv("CONTENT_LENGTH"));
for(x=0;cl && (!feof(stdin));x++)
{m=x;entries[x].val
= fmakeword(stdin,'&',&cl); plustospace(entries[x].val);
unescape_url(entries[x].val);
entries[x].name = makeword(entries[x].val,'=');
}
printf("<H1>Query
Results</H1>");
printf("You submitted
the following name/value pairs:<p>%c",10);
printf("<ul>%c",10);
for(x=0; x <= m; x++)
printf("<li>
<code>%s = %s</code>%c",entries[x].name,
entries[x].val,10);
printf("</ul>%c",10);
}
Надо отметить, что post-query не обрабатывает имена, поэтому в
примере они даны на английском языке. Если Вы используете русские
названия имен, то вы должны обработать имена также как и значения,
т.е. заменить все символы "+" на пробелы и преобразовать
шестнадцатеричные коды кириллических символов в сам символ.
Приведем также исходный текст функций используемых post-query
char *makeword(char *line,
char stop) {
/*
Предназначена для выделения
части строки, ограниченной "стоп-символами"*/
int x = 0,y;
char *word = (char *) malloc(sizeof(char)
* (strlen(line) + 1));
for(x=0;((line[x]) &&
(line[x] != stop));x++)
word[x] = line[x];
word[x] = '\0';
if(line[x]) ++x;
y=0;
while(line[y++] = line[x++]);
return word;
}
char *fmakeword(FILE *f,
char stop, int *cl) {
/*
Предназначена для выделения
строки,
ограниченной "стоп-символом" stop,
из потока f
длиной cl.
*/
int wsize;
char *word;
int ll;
wsize = 102400;
ll=0;
word = (char *) malloc(sizeof(char)
* (wsize + 1));
while(1) {
word[ll] = (char)fgetc(f);
if(ll==wsize) {
word[ll+1] = '\0';
wsize+=102400;
word = (char *)realloc(word,sizeof(char)*(wsize+1));
}
--(*cl);
if((word[ll] == stop)
|| (feof(f)) || (!(*cl))) {
if(word[ll] != stop)
ll++;
word[ll] = '\0';
return word;
}
++ll;
}
}
char x2c(char *what) {
/* Предназначена для преобразования
шестнадцатиричного кода символа в код символа
*/
register char digit;
digit = (what[0] >= 'A'
? ((what[0] & 0xdf) - 'A')+10 : (what[0] - '0'));
digit *= 16;
digit += (what[1] >= 'A'
? ((what[1] & 0xdf) - 'A')+10 : (what[1] - '0'));
return(digit);
}
void unescape_url(char
*url) {
register int x,y;
for(x=0,y=0;url[y];++x,++y)
{
if((url[x] = url[y])
== '%') {
url[x] = x2c(&url[y+1]);
y+=2;
}
}
url[x] = '\0';
}
void plustospace(char
*str) {
/*замена символов "+"
на символ "пробел"*/
register int x;
for(x=0;str[x];x++) if(str[x]
== '+') str[x] = ' ';
}
Для демонстрации реализации формы с методом запроса GET воспользуемся той же самой формой, что и для метода POST и программой query. Для этого изменим значение атрибутов ACTION и METHOD в теге FORM.
<FORM action="http://iceman.cnit.nsu.ru/cgi-bin/query" METHOD=GET>
После инициации формы сервер установит следующие значения для
переменных окружения и аргументов командной строки:
argc = 0. argv is =
SERVER_SOFTWARE = NCSA/1.5.1
SERVER_NAME = iceman.cnit.nsu.ru
GATEWAY_INTERFACE = CGI/1.1
SERVER_PROTOCOL = HTTP/1.0
SERVER_PORT = 80
REQUEST_METHOD = GET
HTTP_ACCEPT = image/gif, image/x-xbitmap, image/jpeg, image/pjpeg,
*/*
PATH_INFO =
PATH_TRANSLATED =
SCRIPT_NAME = /cgi-bin/test-cgi
QUERY_STRING = RealName=%CF%E5%F2%F0%EE%E2+%C8%E2%E0%ED+%D1%E8
%E4%EE%F0%EE%E2%E8%F7&Sex=%CC%F3%E6%F1%EA%EE%E9&Submit=%CF%EE
%F1%EB%E0%F2%FC+%E7%E0%EF%F0%EE%F1
REMOTE_HOST = fwa.cnit.nsu.ru
REMOTE_ADDR = 193.124.209.74
REMOTE_USER =
AUTH_TYPE =
CONTENT_TYPE =
CONTENT_LENGTH =
Как мы видим, выходной поток от формы появился в значении переменной QUERY_STRING.
Результат работы query полностью совпадает с результатом работы post-query.
<FORM атрибуты>...</FORM>
использование: предназначен для получения информации от клиента и определяет начало и конец формы.
атрибуты:
Важно: Формы не могут быть вложенными!
Для реализации формы используются следующие теги.
<INPUT>
использование: предназначен для создания различных по своей функциональности полей ввода.
атрибуты:
TYPE - определяет тип поля формы.
<TEXTAREA атрибуты>...</TEXTAREA>
использование: предназначен для определения области ввода текста. Размер поля определяется атрибутами.
атрибуты:
NAME - значение этого атрибута определяет идентификатор
поля. Возвращается при инициации формы.
ROWS - определяет количество строк в текстовой
области.
COLS - определяет количество столбцов в текстовой
области.
[VALUE] - задает значение по умолчанию.
[DISABLED] - определяет поле как "read only"
- только для чтения. Значение в поле не может быть изменено пользователем.
[ERROR] - определяет сообщение об ошибке, объясняющее,
почему введенное значение в поле не верно.
<SELECT атрибуты>
<OPTION > значение1
...
<OPTION > значениеN
</SELECT>
использование: предназначен для определения области выбора из нескольких значений (меню).
Атрибуты:
NAME - значение этого атрибута определяет идентификатор
поля. Возвращается при инициации формы.
[SIZE] - определяет количество видимых возможных значений.
[MULTIPLE] - определяет возможность множественного выбора.
[DISABLED] - определяет меню как "read only"
- только для чтения. Значения в меню не может быть выбрано пользователем
и показывается серым цветом.
<OPTION атрибуты> значение
использование: используется только с <SELECT> для определения пунктов меню.
атрибуты:
SELECTED - определяет значение по умолчанию
VALUE - определяет возвращаемое значение
Примечание: в [ ] даны необязательные атрибуты
5.1Введение
5.3Администрирование Cold Fusion
5.4Взаимодействие Cold Fusion с базами данных
5.5Передача параметров в DBML - шаблон
5.6Занесение и модификация данных с использованием тегов DBINSERT и DBUPDATE
5.7Выполнение запросов к базам данных
5.8Использование результатов запроса для динамического создания HTML - документа
5.9Вывод результата выполнения запроса в виде таблицы
5.10Дополнительные замечания по созданию DBML - шаблонов
5.11Использование параметров и переменных в шаблонах
5.11.1Поля формы и параметры URL
5.11.2Переменные окружения CGI
5.11.3Применение тега DBSET для создания переменных
5.11.4HTTP Cookies
5.11.5Использование результатов выполнения запросов
5.12Проверка корректности данных и форматирование вывода
5.12.1Проверка корректности данных в полях формы
5.12.2Функции вывода в DBML
5.13Динамическое изменение содержимого документа
5.13.1Условный оператор (DBIF & DBELSE)
5.13.2Перенаправление на другой URL (DBLOCATION & DBABORT)
5.13.3Включение в шаблон других шаблонов
5.13.4Определение типа данных MIME для содержимого документа
5.14Расширенные возможности
5.14.1Динамическое определение SQL выражения
5.14.2Поддержка транзакций
5.14.3Вложенные области вывода и группирования
5.14.4Использование списочных полей с множественным выбором
5.14.5Дополнительные команды SQL
При подготовке данной главы отчета использовались материалы " Cold Fusion User Guide " (Руководство пользователя пакета Cold Fusion).
Пакет Cold Fusion фирмы Allaire - это средство для быстрой разработки интерактивных, динамических документов для Web основанное на обработке информации из баз данных, в основе которого лежит следующий набор технологий:
Разработка приложений с использованием Cold Fusion не требует программирования на таких языках как Perl, C/C++, Visual Basic или Delphi. Вместо этого вы создаете приложение, встраивая в обычный (стандартный) HTML файл специальные теги для работы с базами данных.
В данной главе рассматривается Cold Fusion версии 1.5 .
Cold Fusion запускается как CGI приложение на различных Web-серверах под Windows NT и Windows 95 и должен быть совместим с любым сервером поддерживающим CGI.
Cold Fusion тестировался на совместимость со следующими серверами:
Для связи с различными СУБД Cold Fusion использует 32-разрядные ODBC - драйвера. Для корректной работы с Cold Fusion ODBC - драйвер должен удовлетворять следующим требованиям:
Для установки и использования Cold Fusion система должна удовлетворять следующим требованиям:
Для установки Cold Fusion нужно запустить программу SETUP.EXE, которая должна находится на инсталляционном диске 1.
Помимо копирования файлов, необходимых для работы Cold Fusion, в процессе установки, в корневой директории с документами Web сервера создается директория с именем CFPRO. Эта директория содержит:
Чтобы проверить правильность установки Cold Fusion, нужно открыть документ, URL до которого имеет вид http://myserver/cfpro/getstart.htm, где myserver - имя или IP адрес вашего Web сервера.
Для администрирования в Cold Fusion предусмотрен специальный интерфейс администратора. Этот интерфейс позволяет изменять различные параметры настройки Cold Fusion по четырем категориям:
Cold Fusion позволяет динамически генерировать HTML документы основанные на запросах пользователя. Эти запросы передаются в Cold Fusion CGI - скрипт (DBML.EXE), который пересылает данные в Cold Fusion Engine обрабатывающий эти данные в соответствии с заданным шаблоном, выполняя необходимые запросы и генерируя HTML документ, который отправляется пользователю.
Основой динамического создания документов являются специальные теги, входящие в язык разметки DBML, ориентированные на работу с базами данных. Почти все основные возможности Cold Fusion сосредоточены в четырех тегах:
Шаблон, на основе которого генерируется HTML - документ, представляет собой комбинацию тегов HTML и DBML:
На рисунке 5-1 показывается, как Cold Fusion обрабатывает запрос, полученный от клиента:
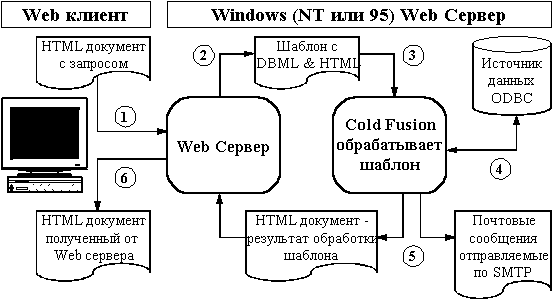
Существует несколько способов передачи параметров между шаблонами. Можно передавать параметры непосредственно в URL, использовать для этого форму либо cookie.
Если параметры передаются через URL, то они добавляются к адресу вызываемого шаблона через символ "&" (амперсант) в виде параметр = значение. Например, гипертекстовая ссылка, приведенная ниже, отправляет параметр с именем 'user_id' и значением 5 в шаблон 'example.dbm':
<A HREF="cgi-shl/dbml.exe?Template=example.dbm&user_id=5">
При передаче параметров через форму используются поля формы, которые должны иметь имена, совпадающие с именами параметров, которые требуется передать. Ниже приведен пример передачи параметра, из предыдущего примера используя форму:
<FORM ACTION="cgi-shl/dbml.exe?Template=example.dbm">
<INPUT TYPE="HIDDEN"
NAME="user_id" VALUE="5">
<INPUT TYPE="SUBMIT"
VALUE="Enter">
</FORM>
Заметим, что при обращении к CGI - программе DBML.EXE должен быть определен стандартный параметр Template, указывающий на конкретный шаблон.
Переменные, занесенные в cookie браузера и переменные окружения CGI доступны в любом шаблоне. Способы занесения информации в cookie описаны в п.5.11.
При использовании тегов DBINSERT и DBUPDATE для занесения или модификации данных, параметры должны быть переданы в шаблон обязательно из формы, используя метод POST.
Для создания новой записи в базе данных используется тег DBINSERT, а для модификации существующей записи используется тег DBUPDATE. При использовании этих тегов необходимо определить атрибуты DATASOURCE и TABLENAME. DATASOURCE это название источника данных ODBC, содержащего редактируемую таблицу, а TABLENAME - имя этой таблицы.
Например, если источник данных ODBC называется 'Person DB', а таблица, в которой требуется создать запись - 'Person', то тег DBINSERT в шаблоне будет иметь следующий вид:
<DBINSERT DATASOURCE="Person DB" TABLENAME="Person">
Параметры, переданные в шаблон должны совпадать с именами полей таблицы, в которой создается (модифицируется) запись. В том случае, если не все передаваемые параметры должны участвовать в этой процедуре, используется атрибут FORMFIELDS, в котором через запятую перечисляются имена полей таблицы, для которых должны существовать одноименные параметры.
Особо следует отметить, что для того, чтобы использовать тег DBUPDATE для модификации записи, в таблице должен быть определен первичный ключ, а для всех полей включенных в первичный ключ из обрабатываемой HTML-формы обязательно должны быть переданы соответствующие параметры.
Теги DBINSERT и DBUPDATE могут иметь также еще два необязательных атрибута:
Пример
Пусть определена HTML -
форма для ввода данных:
<HTML>
<HEAD>
<TITLE>Пример ввода данных
для создания записи</TITLE>
</HEAD>
<BODY>
<FORM ACTION="/cgi-shl/dbml.exe?Template=example.dbm"
METHOD="POST">
ФИО : <INPUT TYPE="Text"
NAME="FullName">
Телефон : <INPUT TYPE="Text"
NAME="Phone">
Дата рождения : <INPUT TYPE="Text"
NAME="Birthday">
</FORM>
</BODY>
</HTML>
Следующий шаблон, example.dbm, которому будут переданы данные из формы создает запись в таблице и выдает подтверждающее сообщение:
<DBINSERT DATASOURCE="Person
DB" TableName="Persons"
FORMFIELDS="FullName,Phone,Birthday">
<HTML>
<HEAD><TITLE>Подтверждение</TITLE></HEAD>
<BODY>
<H1>Запись создана!</H1>
</BODY>
</HTML>
Для выполнения запросов к базе данных используется тег DBQUERY. Этот тег имеет следующий синтаксис:
<DBQUERY NAME="имя запроса"
DATASOURCE="имя источника данных odbc"
SQL="sql выражение"
TIMEOUT=n MAXROWS=n DEBUG>
Атрибут NAME определяет имя запроса, которое используется далее для отображения результата выполнения запроса. Имя запроса должно начинаться с буквы и может содержать буквы и цифры (пробелов быть не должно).
Атрибут DATASOURCE задает имя источника данных ODBC, который должен быть создан с помощью интерфейса администратора Cold Fusion.
Ключевым атрибутом тега DBQUERY, является атрибут SQL, который собственно и определяет запрос к базе данных на языке SQL (для улучшения читабельности, допускается расположение значения атрибута SQL на нескольких строках).
Создавая SQL запрос, следует помнить, что конкретная база данных может иметь свои особенности в синтаксисе SQL, использование которых ограничивается этой базой данных. Чтобы проверить, является ли конкретное SQL выражение совместимым с ODBC и независимым от конкретной базы данных, лучше всего использовать Microsoft Query, входящий в состав Microsoft Office. Для этого нужно в меню Microsoft Query выбрать "Файл/Выполнить SQL", в появившемся окне диалога ввести предложение SQL, выбрать источник данных ODBC, нажав на кнопку "Источники...", после чего нажать на кнопку "Выполнить". Этот продукт можно также использовать и для создания SQL - выражений, используя для этого визуальные средства создания запросов. Получить SQL - выражение созданного таким образом запроса можно нажав на кнопку "SQL" в панели инструментов.
Атрибут MAXROWS является необязательным и определяет максимальное количество записей, которые могут быть возвращены в результате выполнения запроса.
Атрибут TIMEOUT также является необязательным и определяет максимальное количество миллисекунд для выполнения запроса, до выдачи сообщения об ошибке. Заметим, что этот атрибут поддерживается только некоторыми ODBC - драйверами (например, драйвером для MS SQL Server 6.0).
Атрибут DEBUG используется для отладки запросов. При наличии этого атрибута пользователю отправляется дополнительная информация о выполнении этого запроса, такая как текст выполненного SQL - запроса, число возвращенных записей и др.
Приведем пример запроса с именем 'AllPersons', который возвращает все записи таблицы 'Persons' из базы данных, с которой связан источник данных ODBC с именем 'Person DB':
<DBQUERY NAME="AllPersons"
DATASOURCE="Person DB"
SQL="select * from Persons">
Для динамической настройки SQL - выражения можно использовать параметры, переданные в шаблон. Это могут быть параметры, переданные из формы, URL, а также переменные CGI. Параметры, используемые внутри SQL - выражения, должны быть обрамлены символом "#" (например #Name#). При обработке запроса Cold Fusion ищет параметр с таким именем среди параметров, полученных из формы, в URL или среди переменных CGI. При нахождении подходящего параметра его значение подставляется вместо соответствующей ссылки на параметр.
Примеры использования параметров в SQL -выражении
Пример 1
Предположим что обрабатывается URL
"/cgi-shl/dbml.exe?Template=prs.dbm&Id=22",
а атрибут SQL в DBQUERY имеет вид
SQL="select * from Persons where Id = #Id#",
тогда в базу данных будет передано следующее SQL - выражение:
select * from Persons where Id = 22 .
Пример 2
Предположим, что в шаблон передан параметр FirstLetters
и нужно найти в таблице Persons
записи, в которых первые
буквы в поле FullName совпадают
со значением этого параметра. Значение атрибута SQL
в этом случае будет следующим:
SQL="select * from Persons
where FullName like '#FirstLetters#%'"
Следует обратить внимание на то, что маска, состоящая из параметра и символа '%', в отличие от предыдущего примера, обрамлена одинарными кавычками. Это связано с тем, что поле Id из примера 1 имеет числовой тип, а поле FullName - текстовый тип (синтаксис SQL требует, чтобы текстовые значения всегда были обрамлены одинарными кавычками).
Для того чтобы задать маску, в примере использовался символ '%', который в SQL - запросах соответствует произвольной последовательности символов. Также для определения маски может использоваться символ '_' (подчерк), соответствующий одному произвольному символу.
Для вывода данных возвращаемых в результате выполнения запроса определенного в DBQUERY применяется тег DBOUTPUT. Внутри этого тега, связанного с конкретным запросом, может находиться обычный текст, теги HTML, ссылки на поля определенные в запросе. При обработке шаблона, содержимое тега DBOUTPUT отправляется клиенту для каждой записи, возвращаемой в результате выполнения запроса, с подстановкой соответствующих значений параметров и полей.
Тег DBOUTPUT имеет следующий синтаксис:
<DBOUTPUT QUERY="имя
запроса" MAXROWS=n>
Текст, теги HTML,
ссылки на поля и параметры (т.е.
#Name#)
</DBOUTPUT>
Атрибут QUERY применяется для указания имени запроса DBQUERY, результат выполнения которого будет использоваться, а атрибут MAXROWS определяет максимальное количество записей этого запроса, которые будут переданы для вывода в тег DBOUTPUT.
Пример
Для вывода результата выполнения запроса с именем 'AllPersons',
отображая имя персоны и телефон, и разделяя записи горизонтальной
линией, может использоваться следующая конструкция:
<DBOUTPUT QUERY="AllPersons"
MAXROWS=50>
<HR>
#FullName# (Телефон: #Phone#
) <BR>
</DBOUTPUT>
Результат обработки этого тега будет иметь вид:
<HR>
Иванов Иван Иванович (Телефон:
222-22-22 ) <BR>
<HR>
Петров Петр Петрович (Телефон: 444-44-44 ) <BR>
Теги DBTABLE и DBCOL всегда употребляются вместе для отображения результата выполнения запроса в виде таблицы.
Атрибуты тега DBTABLE:
| - имя DBQUERY, для которого нужно отобразить данные; | |
| - максимальное количество записей, которое может быть отображено в таблице; | |
| - количество пробелов, которые будут вставлены между колонками (по умолчанию 2); | |
| - количество строк, которые будут отведены для заголовка (по умолчанию 2); | |
| - при наличие этого тега результат запроса будет отображен в виде HTML - таблицы, в противном случае будет использован тег HTML <PRE>. | |
| - используетя только вместе с атрибутом HTMLTABLE для отображения рамки в таблице. |
Атрибуты тега DBTABLE:
| - текст, который будет выводиться как заголовок колонки; | |
| - ширина колонки в символах (по умолчанию 20); | |
| -выравнивание содержимого колонки (LEFT, RIGHT и CENTER); | |
| -заключенный в кавычки текст, определяющий содержимое колонки, в котором могут находиться те же теги, ссылки на параметры и др., что и в теге DBOUTPUT. |
Приведем пример использования тегов DBTABLE и DBCOL:
<DBTABLE QUERY "AllPersons"
MAXROWS=20>
<DBCOL HEADER="Фамилия
Имя Отчество" WIDTH="30" TEXT="#FullName#">
<DBCOL HEADER="Телефон"
WIDTH="10" TEXT="#Phone#">
<DBCOL HEADER="Дата рождения"
WIDTH="9" TEXT="# DateFormat(Birthday)#">
</DBTABLE>
SQL="select ""Full Name"" as FullName from Persons"
Псевдонимы бывает, также, полезно применять для удобства, в случаях, если имя поля велико.
Если в шаблон, с помощью полей формы или в URL, были переданы параметры, то внутри любого тега DBML к этим параметрам можно обращаться, используя следующий синтаксис: #Form.Name#, #URL.Name#. На самом деле, префиксы 'Form.' и 'URL.' могут опускаться, если заранее известно, что не может быть параметров других типов с такими же именами. Это правило относится ко всем типам параметров и переменных.
Каждый сеанс связи вызывающий CGI - программу имеет конкретные переменные окружения. Доступ к ним из шаблона осуществляется, также как и к другим параметрам, только используется префикс 'CGI.', например #CGI.REMOTE_ADDR#.
С помощью тега DBSET можно создавать переменные непосредственно в самом шаблоне и использовать их. Приведем пример, в котором создается переменная #UserId# и ей присваивается значение 10.
В правой части операции присваивания в DBSET, может находиться как число, текст (заключенный в кавычки), так и любые параметры доступные в шаблоне, например #CGI.SCRIPT_NAME#. Обращаясь к этим переменным, следует использовать префикс Variable, например #Variable.UserId#.
Cookies - это механизм, позволяющий приложениям о стороны сервера сохранять и использовать параметры на стороне клиента. Этот механизм поддерживается всеми версиями Netscape Navigator, MS Internet Explorer начиная с версии 2.0, и будет поддерживаться остальными Web - браузерами в ближайшем будущем.
Для сохранения параметров в Cookies. Используется тег DBCOOKIE, имеющий следующий синтаксис:
<DBCOOKIE NAME="Имя_параметра" VALUE="Значение параметра" EXPIRES="Срок действия" SECURE>
В атрибутах NAME и VALUE определяются имя и значение параметра соответственно. Атрибут EXPIRES определяет, когда закончится срок действия этого параметра. Этот атрибут может быть задан как дата т.е. '10/09/97', количество дней (т.е. 10, 100), NOW (удаляет параметр) или NEVER. Наличие необязательного атрибута SECURE запрещает отправлять параметр браузеру, если тот не поддерживает стандарт SSL.
К параметрам, хранимым в cookies можно обращаться внутри любого тега DBML, добавляя префикс 'Cookies.', например:
<DBOUTPUT>
#Cookies.User_Id#
</DBOUTPUT> .
После выполнения запроса, результат его выполнения может быть использован в качестве динамического параметра для спецификации другого запроса. Например, если создан запрос с именем 'FindUser', который возвращает идентификатор записи, расположенный в поле 'USER_ID', то можно использовать этот идентификатор в другом запросе, используя имя запроса как префикс к имени поля, разделяя их точкой (т.е. #FindUser.UserId#).
Каждый запрос, описанный тегом DBQUERY, после выполнения имеет два специальных атрибута, RecordCount и CurrentRow, содержащих информацию о количестве возвращенных в результате выполнения запроса записей и о текущей записи, обрабатываемой тегом DBOUTPUT, соответственно. Используются эти атрибуты так же как и поля запроса (#FindUser.RecordCount#).
В Cold Fusion предусмотрен механизм проверки корректности заполнения полей формы. Этот механизм основан на добавлении в форму дополнительных полей типа HIDDEN (скрытые), с именем, составленным из имени поля, значение которого нужно проверить и одного из допустимых в Cold Fusion суффиксов, задающих контекст проверки.
В следующей таблице приведен список всех суффиксов используемых для проверки:
| Суффикс | Значение атрибута VALUE | Описание |
| _required | Текст сообщения об ошибке | Проверяется произведен ли ввод в поле формы. |
| _integer | Текст сообщения об ошибке | Проверяется, является ли значение, введенное пользователем, целым числом. |
| _float | Текст сообщения об ошибке | Проверяется, является ли значение, введенное пользователем, числом. |
| _range | MIN = Минимальное_Значение
MAX = Максимальное_Значение | Проверяется, находится ли введенное число в определенных границах. |
| _date | Текст сообщения об ошибке | Проверяется, находится ли введенная пользователем дата в одном из следующих форматов: DD/MM/YY, DD/MM/YYYY, DD/MM (используется текущий год). В качестве разделителя можно, также, использовать тире (т.е. DD-MM-YY). |
Пример
Ниже приведен фрагмент описания формы, состоящий из двух текстовых
полей: обязательное для заполнения
поле FullName и поле типа
дата Birthday, и для каждого
из этих полей описано поле типа HIDDEN
задающее контекст проверки.
Фамилия Имя Отчество :
<INPUT TYPE="TEXT" NAME="FullName">
<INPUT TYPE="HIDDEN"
NAME="FullName_required"
VALUE="Фамилия Имя Отчество
должны быть заданы!">
Дата рождения : <INPUT TYPE="TEXT"
NAME="Birthday">
<INPUT TYPE="HIDDEN"
NAME="Birtday_date"
VALUE="Дата рождения должна
быть в формате DD/MM/YYYY (например, 20.08.1968)">
Для отображения, данные в нужном формате, в Cold Fusion предусмотрены специальные функции. При использовании такой функции, примененной к конкретному параметру, она заключается в символ '#', например, #DateFormat(Form.LastUpdate)#.
Список основных функций
| Функция | Описание | Пример |
| DateFormat | Отображает поле базы данных типа 'дата/время' или 'дата' в формате DD/MM/YY. | 12/01/96 |
| TimeFormat | Отображает поле базы данных типа 'дата/время' в формате HH:MI AM/PM.. | 10:22 AM |
| NumberFormat | Отображает числовые значения как целые числа, разделяя разряды запятой. | 10,256 |
| DecimalFormat | То же, что и NumberFormat, плюс отображаются два знака после десятичной точки. | 10,256.3 |
| DollarFormat | То же, что и DecimalFormat, плюс добавляется символ $ и вместо знака минус перед отрицательным значением оно помещается в скобки. | $10,256.73 |
| YesNoFormat | Отображает данные логического типа как Yes или No. Все ненулевые значения интерпретируются как Yes, нуль - как No. | Yes |
| ParagraphFormat | Применяется при отображении данных введенных в поле TEXTAREA. Преобразует символ перевода строки в пробел, два перевода строки подряд - в тег параграфа HTML (<P>). | |
| HTMLCodeFormat | Удаляет символ перевода строки и пропускает все специальные символы (>, <, ", &), применяя к тексту тег преформатирования HTML (<PRE>). | |
| HTMLEditFormat | То же, что и HTMLCodeFormat, только без добавления тега <PRE>. |
Кроме вышеперечисленных есть еще несколько функций обеспечивающих дополнительные возможности манипулирования параметрами в шаблоне:
Эта функция проверяет, доступен ли в шаблоне параметр с заданным именем, возвращая Yes или No. Например, чтобы проверить был ли отправлен из формы параметр UserId, используется следующее выражение:
<DBIF #ParameterExists(Form.UserId)# is Yes>
Эта функция обычно используется в SQL выражениях для устранения из значений параметров одиночных кавычек, которые являются специальным символом в SQL. Приведем пример использования этой функции:
SELECT * FROM Persons WHERE
FullName Like '#PreserveSingleQuotes(Form.FullName)#%'
Функция заменяет пробелы на символ "+" и все не латинские символы и цифры - шестнадцатеричным эквивалентом, что позволяет использовать результат в строке URL.
Эти функции возвращают переданный им параметр, прибавив или отняв от него единицу соответственно. Например, чтобы увеличить параметр 'OrderCount' можно воспользоваться следующим выражением:
<DBSET #OrderCount# = #IncrementValue(OrderCount)#
Используя в качестве аргумента имя поля конкретного запроса, эти функции возвращают разделенный запятыми список значений этого поля для каждой записи, возвращенной в результате выполнения запроса.
Например, если запрос возвращает четыре записи, то результат функции ValueList будет иметь вид 11,22,33,44, а результат функции QuotedValueList, примененной к этим же данным, будет возвращать '11','22','33','44'.
Эти функции могут применятся для использования результата одного запроса в операции IN последующего запроса, например:
<DBQUERY NAME="Customers"
...определение запроса...>
<DBQUERY
NAME="CustomerOrders" DATASOURCE="EXAMPLE"
SQL="SELECT * FROM Orders
WHERE Customer_ID
IN ( #ValueList(Customer.CustomerID)#
)">
Основным средством динамического определения содержимого документа являются теги DBIF и DBELSE, позволяющие производить проверку некоторого условия и в зависимости от этого формировать результат.
Тег DBIF имеет следующий синтаксис (тег DBELSE может не использоваться):
<DBIF значение оператор
значение>
теги HTML и DBML
<DBELSE>
теги HTML и DBML
</DBIF>
В качестве элемента тега DBIF - "значение", могут использоваться любой параметр или переменная Cold Fusion (например, #Form.Name#, #CGI.User_Agent#), числовое значение, произвольная последовательность символов (заключенная в кавычки).
Элемент тега DBIF - "оператор" ограничивается следующим списком:
Пример
<DBIF #PersonSearch.RecordCount()#
is 0>
<P>Лиц, удовлетворяющих
заданным критериям поиска,
в базе данных не обнаружено!
<DBELSE>
<DBOUTPUT QUERY="PersonSearch">
<HR>
Фамилия Имя Отчество:
#FullName# <BR>
<DBIF #Phone# is "">
Телефон:
#Phone# <BR>
<DBIF>
</DBOUTPUT>
</DBIF>
Для перенаправления пользователя на другой URL предназначен тег DBLOCATION. Этот тег обычно применяется, если в шаблоне выполняется один или более запросов, а затем нужно сразу же перейти к другому документу, либо URL, на который нужно отправит пользователя, зависит от параметра. Приведем пример использования тега, иллюстрирующий его синтаксис:
<DBIF #NewPassword# is not
#PasswordConfirmation#>
<DBLOCATION URL="/login/invalidpassword.html">
</DBIF>
В качестве значения атрибута URL тега DBLOCATION можно использовать параметры и переменные, допустимые в шаблоне. Например, <DBLOCATION URL=#Page#>.
Для прерывания обработки шаблона в Cold Fusion используется тег DBABORT.
<P>Этот текст будет отправлен
клиенту
<DBABORT>
<P>Этот текст не будет
отправлен клиенту
Обычно этот тег используется при неправильной аутентификации.
По мере усложнения приложений, разрабатываемых с использованием Cold Fusion, появляется необходимость упростить используемые шаблоны. Одним из способов решения этой проблемы, предлагаемых в Cold Fusion, является выделение из шаблонов часто используемых блоков, таких как запросы и области вывода, и их многократное использование в других шаблонах. Для включения часто используемых шаблонов в другой шаблон, используется тег DBINCLUDE.
Тег DBINCLUDE может быть расположен в любом месте шаблона, кроме как в тегах DBQUERY, DBOUTPUT и DBTABLE. Тег DBINCLUDE имеет атрибут TEMPLATE который задает путь до файла с шаблоном. Этот шаблон будет обработан Cold Fusion как часть основного шаблона (то есть, в нем могут использоваться запросы, уже запущенные в основном шаблоне, а также ссылки на параметры формы, URL и CGI).
Приведем пример включения в шаблон шаблона с именем 'test.dbm':
<DBINCLUDE TEMPLATE="test.dbm">
Cold Fusion позволяет задавать тип MIME для данных которые будут отправлены пользователю из текущего шаблона (по умолчанию используется text/html). Для этого используется тег DBCONTENT, имеющий единственный атрибут TYPE, который, собственно, и задает тип данных. Например, чтобы отправить клиенту VRML - документ может использоваться следующий шаблон:
<DBCONTENT TYPE="x-world/x-vrml">
<DBQUERY NAME="GetCyberRoom"
SQL="SELECT VRML_Script
FROM CyberRooms WHERE
RoomNumber=#URL.RoomNumber#">
<DBOUTPUT QUERY="GetCyberRoom">
#VRML_Script#
</DBOUTPUT>
Заметим, что Cold Fusion не будет отправлять клиенту текст, расположенный до тега DBOUTPUT.
В некоторых сложных приложениях может потребоваться, в зависимости от значений параметров, определять не только содержание запроса, но и его структуру. В Cold Fusion предусмотрен тег DBSQL, который может употребляться внутри тега DBQUERY, доопределяя SQL - выражение, в зависимости от значений параметров. Тег DBSQL имеет единственный атрибут SQL, значение которого будет добавляться к основному SQL - выражению.
Пример
<DBQUERY NAME="SiteSearch"
DATASOURCE="Sites Database"
SQL="SELECT * FROM SITES
WHERE SiteType = #SiteType# ">
<DBIF #Form.City# is not "">
<DBSQL SQL=" AND City
= '#Form.City#' ">
</DBIF>
<DBIF #Form.SortOrder# is
not "">
<DBSQL SQL=" ORDER BY
#Form.SortOrder# ">
</DBIF>
</DBQUERY>
Для объединения нескольких запросов в одну транзакцию может быть использован тег DBTRANSACTION. Все запросы, содержащиеся внутри этого тега, будут интерпретироваться как одна транзакция. То есть все изменения сделанные в базе данных, либо будут одновременно сохранены, либо не будет сохранено ни одно из них.
Приведем пример, в котором денежная сумма переводится с одного банковского счета на другой:
<DBTRANSACTION>
<DBQUERY NAME="WithdrawCash"
DATASOURCE="Bank Accounts"
SQL = "UPDATE Accounts
SET Balance = Balance - #Amount#
WHERE Account_ID = #AccountFrom#
">
<DBQUERY NAME="DepositCash"
DATASOURCE="Bank Accounts"
SQL = "UPDATE Accounts
SET Balance = Balance + #Amount#
WHERE Account_ID = #AccountTo#
">
</DBTRANSACTION>
Заметим, что не все драйверы ODBC поддерживают транзакции. Например, драйверы для Oracle, SQL Server и Access поддерживают транзакции, а драйверы для FoxPro, dBase и Paradox - нет.
Теги DBOUTPUT могут вкладываться друг в друга, с целью сгруппировать области вывода. Группирование достигается с помощью использования атрибута GROUP в теге DBOUTPUT, который содержит другой тег DBOUTPUT. Этот атрибут определяет поле по которому будет производится группирование. Внешний тег DBOUTPUT обычно используется для вывода заголовка группы , а внутренний - для вывода записей содержащихся в группе.
Приведем пример вывода сотрудников организации сгруппированных по отделам:
<DBQUERY NAME="ListEmployees"
DataSource="Employees"
SQL="SELECT * FROM Emp ORDER
BY Department">
<DBOUTPUT QUERY="ListEmployees"
GROUP="Department">
<P> <H2>#ListEmployees.Department#</H2>
<UL>
<DBOUTPUT>
<LI> #FullName# ##
</DBOUTPUT>
</UL>
</DBOUTPUT>
Обратим внимание на то, если поле используется для группирования, то результат запроса должен быть отсортирован по этому полю. Если используется многоуровневое группирование (ограничений на количество уровней вложенности тегов DBOUTPUT нет), то соответственно в SQL - выражении должна быть задана многоуровневая сортировка (например, ORDER BY Country, Region).
Если HTML - форма содержит поле типа SELECT с множественным выбором, либо поля с одинаковыми именами (например, поля типа checkbox), то данные будут переданы в шаблон в виде, разделенных запятыми, списка значений. Такая форма представления наиболее удобна для использования в операторе IN языка SQL.
Пример
Предположим, что в форме содержится поле:
<SELECT NAME="SelectedPersons"
MULTIPLE SIZE="3">
<OPTION VALUE="1">Иванов
И.И.
<OPTION VALUE="2">Петров
П.П.
<OPTION VALUE="3"
SELECTED>Сидоров С.С.
</SELECT>
Этот параметр, переданный в шаблон, может быть использован в следующем SQL - выражении:
SQL="SELECT * FROM Persons
WHERE Person_ID IN ( #SelectedPersons#
)
Следует обратить внимание на то, чтобы параметр, который используется в операторе IN, был не пуст. Для этого можно пользуясь стандартными средствами Cold Fusion описать поле как требуемое, либо использовать поле типа HIDDEN с тем же именем и с заведомо неверным значением. Например, предыдущий пример можно дополнить следующим полем:
<INPUT TYPE="HIDDEN" NAME="SelectedPersons" VALUE="-1">
В теге DBOUTPUT, кроме выражения SELECT языка SQL, допускается использование и любых других, допустимых для конкретного источника данных, SQL - команд, включая:
Использование непосредственно команд SQL вместо тегов DBINSERT и DBUPDATE в некоторых случаях может обеспечить большую гибкость и эффективность. Например, при модификации или создании новой записи, появляется возможность использовать все параметры и переменные доступные в шаблоне в том числе и результаты определенных в шаблоне запросов. Пример использования команды UPDATE в теге DBQUERY приведен в п.5.14.2.
6.1Основные особенности Perl
6.1.1Введение
6.2Взаимодействие с СУБД
6.2.1Взаимодействие с Oracle
6.2.1.1Основные функции доступа
6.2.1.2Дополнительные функции
6.2.1.3Переменные
6.2.1.4Переменные для подстановки
6.4Обработка файлов формата DBF
Perl - интерпретируемый язык, приспособленный для обработки произвольных
текстовых файлов, извлечения из них необходимой информации и выдачи сообщений.
Perl также удобен для написания различных системных программ. Этот язык прост
в использовании, эффективен, но про него трудно сказать, что он элегантен и
компактен. Perl сочитает в себе лучшие черты C, shell, sed и awk,
поэтому для тех, кто знаком с ними, изучение Perl-а не представит
особого труда.
Cинтаксис выражений Perl-а близок к синтаксису C. В отличие от большинства
утилит ОС UNIX Perl не ставит ограничений на объем обрабатываемых данных и если
хватает ресурсов, то весь файл обрабатывается как одна строка. Рекурсия может
быть произвольной глубины. Хотя Perl приспособлен для обработки текстовых
файлов, он может обрабатывать так же двоичные данные и создавать .dbm файлы,
подобные ассоциативным массивам. Perl позволяет использовать регулярные
выражения, создавать объекты, вставлять в программу на С или C++ куски
кода на Perl-е, а также позволяет осуществлять доступ к базам данных, в том числе
Oracle.
Этот язык часто используется для написания CGI-модулей, которые, в свою очередь, могут
обращаться к базам данных. Таким образом может осуществляться доступ к
базам данных через WWW.
Perl позволяет осуществлять доступ к различным СУБД. Здесь будет освещен вопрос
доступа к СУБД Oracle.
Мы приведем здесь пример программы, которая создает таблицу, помещает в нее некоторые данные и потом производит выборку строк из этой таблицы.
#!/usr/local/bin/perl use Oraperl; # подключаем модуль Oraperl $system_id = 'T:bdhost.com:Base'; $lda = &ora_login($system_id,'scott','tiger'); # вход в систему $st = 'create table EMP (name varchar2(100), organization varchar2(100))'; $csr = &ora_open($lda,$st) || die $ora_errstr; &ora_close($csr); # создание таблицы в базе данных $st = 'insert into EMP values (\'John Smit\', \'NATO\')'; $csr = &ora_open($lda, $st); &ora_close($csr); # помещение строки в таблицуВ результате в базе создалась таблица из двух столбцов с одной записью:
| Name | Organization |
| John Smit | NATO |
$st = 'select name from EMP where organization = \'NATO\''; $csr = &ora_open($lda,$st); # выбираем из таблицы значения столбца name, # которым сответствует значение столбца organization # равное 'NATO' @result = &ora_fetch($csr); # помещаем эти значения в массив @result &ora_close($csr); print @result; &ora_logoff($lda); # выход из системы
Для взаимодействия с Oracle в Perl есть специальный модуль Oraperl.pm.
Основными функциями для доступа к базе данных являются:
&ora_login
$lda = &ora_login($system_id,$username,$password)Для того, чтобы получить доступ к информации, хранимой в
Oracle необходимо сначала
войти в систему. Это осуществляется вызовом функции &ora_login(). Эта функция
имеет три параметра: системный идентификатор базы данных, имя пользователя в базе
и пароль пользователя. Возвращается идентификатор регистрации в системе (Oracle Login Data Area).
Несколько доступов могут осуществляться одновременно. Эта функция
эквивалентна функции OCI(Oracle Call Interface) olon или orlon.
$csr = &ora_open($lda, $statement [,$cache])Для определения SQL-запроса в базу данных программа должна вызывать функцию
&ora_open. Эта функция имеет как минимум два параметра: идентификатор регистрации
и SQL выражение. Необязательный третий параметр описывает размер буфера строк для
SELECT оператора. Возвращается курсор Oracle. Если третий параметр опущен,
то используется стандартный размер буфера.
$csr = &ora_open($lda,'select ename, sal from emp order by ename',10);Эта функция эквивалентна функции OCI
oopen или oparse.
&ora_bind($csr, $var, ...)Если SQL выражение содержит обращение к переменным языка Perl, то необходимо подставить вместо имен значения переменных. Для этого используется функция
&ora_bind.
$csr = &ora_open($lda, 'insert into emp values (:1,:2)'); &ora_bind($csr,$ename,$sal);- подставляет в SQL выражение вместо :1 и :2 значения переменных
$ename
и $sal.
$nfields = &ora_fetch($csr[, trunc]); @array = &ora_fetch($csr);Эта функция используется с оператором SQL SELECT для извлечения информации из базы данных и имеет только один обязательный параметр - идентификатор курсора, полученный в результате вызова функции
&ora_open. В скалярном
контексте она возвращает число выбранных строк, в списковом - массив выбранных
строк. Второй необязательный параметр содержит информацию о том, можно ли обрезать
данные типов LONG и LONG RAW или выдавать сообщение об ошибке. Если параметр
опущен, то информация берется из переменной $ora_trunc.
Если произошло обрезание данных, то переменная $ora_errno принимает значение
1406. Эта функция эквивалентна функции OCI ofetch.
&ora_close($csr)Если открытый курсор не будет больше использоваться, то его нужно закрыть вызовом функции
&ora_close. Это эквивалентно функции OCI oclose.
&ora_do($lda,$statement)Не все SQL-выражения возвращают данные или содержат переменные для подстановки. В таких случаях функция
&ora_do выступает в качестве альтернативы &ora_open
и &ora_close. Первым параметром является идентификатор регистрации, вторым --
SQL выражение.
&ora_do($lda,'drop table employee');это эквивалентно:
&ora_close(&ora_open($lda, 'drop table employee'));
&ora_logoff($lda)Для выхода из системы используется функция
&ora_logoff. Она эквивалентна функции OCI ologoff.
Дополнительные возможности предоставляются функциями
&ora_titles()
&ora_length()
&ora_types()
&ora_autocommit()
&ora_commit()
&ora_rollback()
&ora_version()
&ora_titles
@titles = &ora_titles($csr)Программа может определить название полей, содержимое которых будет извлечено запросом, вызовом функции
&ora_title. Эта функция имеет один параметр - курсор. Заголовки обрезаются
до длины поля.
@length = &ora_length($csr)Программа может определить длину каждого из полей, возвращенных запросом, с помощью вызова функции
&ora_length. Она имеет только один параметр - курсор и
возвращает массив целых чисел.
@types = &ora_types($csr)Программа может определить тип каждого из полей, возвращенных запросом, с помощью вызова функции
&ora_types. Она имеет один параметр - курсор и возвращает
массив целых чисел. Эти типы определяются в документации по OCI и в файле
oraperl.ph для Oracle v6.
&ora_autocommit($lda,$on_or_off)Режим автоматического завершения транзакций можно установить или отменить вызовом функции
&ora_autocommit. Эта функция имеет два параметра:
идентификатор регистрации и булевскую переменную, которая указывает
действие, которое нужно выполнить. Если значение переменной ненулевое, то
режим включается, если нулевое, то отключается. По умолчанию режим не включен.
Режим включается на продолжительность пребывания в системе. Если есть
необходимость включать его только для одного оператора, то лучше делать
несколько регистраций и использовать для каждого оператора отдельный
идентификатор регистрации.
&ora_commit($lda) &ora_rollback($lda)Изменения в базе данных могут быть сохранены или отменены вызовом этих функций. Они имеют один параметр - идентификатор регистрации в системе. Транзакции, результат которых уже был сохранен не могут быть отменены
&ora_rollback. Эти функции также действуют на все время пребывания в
системе, а не на отдельные операторы.
&ora_version()Эта функция печатает версию и информацию об авторских правах, касающуюся
Oraperl. Она не возвращает ничего.
В модуле Oraperl.pm есть шесть специальных переменных:
$ora_cache
$ora_long
$ora_trunc
$ora_errno
$ora_errstr
$ora_verno
Эти переменные
используются для определения поведения Oraperl в определенных условиях.
$ora_cache
Эта переменная определяет размер буфера для функции
&ora_open() и SELECT-выражения, если точный размер буфера не указан.
Как правило устанавливается размер буфера равный пяти. Присваивание этой
переменной значения, равного нулю, устанавливает значение этой переменной
равным первоначальному значению. Присваивание отрицательной величины
приводит к ошибке.
$ora_long
Обычно Oraperl спрашивает базу данных о длине каждого поля и соответствующим
образом распределяет буферное пространство. Это невозможно для полей типа
LONG и LONGRAW. Распределение пространства в предположении максимально
возможной длины (65535 bytes) привело бы к излишним тратам памяти. Поэтому
когда &ora_open() определяет, что поле имеет тип LONG, память распределяется
согласно значению переменной $ora_long. При инициализации она принимает
значение 80 (для совместимости с продуктами Oracle), но в программе ее
можно устанавливать произвольным образом.
$ora_trunc
Так как Oraperl не может точно определять длину значений
типа LONG, возникают ситуации, когда значение $ora_long недостаточно для
хранения полученных данных. В таком случае, если у &ora_fetch есть
необязательный второй параметр, происходит обрезание данных. Если второй
параметр опущен, то вместо него используется значение $ora_trunc.
$ora_errno
Содержит код ошибки произошедшей при последнем вызове
какой-либо функции. Есть два интересных случая, касающихся &ora_fetch().
В первом случае, если произошло обрезание данных типа LONG или LONGRAW и
обрезание было разрешено, тогда выполнение этой функции полностью успешно,
но $ora_errno принимает значение 1406, для индикации того, что произошло
обрезание. Во втором случае, если &ora_fetch() возвратила false, то
$ora_errno принимает значение 0 в случае конца данных или код ошибки,
если действительно произошла ошибка.
$ora_errstr
Содержит сообщение об ошибке, соответствующее значению
$ora_errno.
$ora_verno
Содержит версию Oraperl в формате v.ppp, где v -
основной номер версии, а ppp - patchlevel.
Oraperl позволяет SQL выражению содержать обращение к переменным языка Perl. Они
состоят из двоеточия и следующего за ним номера. Например:
$csr = &ora_open($lda,"insert into tel values(:1,:2)");Эти два имени :1 и :2 называются переменными для подстановки. Функция
&ora_bind() используется для привязывания переменных к их значениям.
&ora_bind($csr, "Annette","3-222-2-22-22-22"); &ora_bind($csr,$name,$telephone);Номера переменных должны следовать в порядке возрастания начиная с 1, так как
&ora_bind выполняет подстановку именно в таком порядке.
Язык Perl очень широко используется при написании исполняемых модулей
CGI (Common Gateway Interface) для Web.
Это обусловлено прежде всего тем, что Perl предоставляет разработчикам
простые и удобные средства обработки текста и взаимодействия с базами
данных. Наша цель - лишь дать пример
использования Perl для написания CGI-модуля.
Рассмотрим простую подпрограмму разбора входного потока CGI-программы
(при передаче параметров используется метод POST ).
#!/usr/local/bin/perl
sub Print {
$len = 100;
$buf = "";
read(STDIN, $buf,$len);
# считываем из стандартного потока ввода
# в переменную $buf количество символов
# $len
@ar = split(/[&=]/,$buf);
# разбиваем строку в массив строк,
# разделителями служат & и =.
$output = "Content-type: text/html\n\n
# посылает тип MIME передаваемого документа
<HTML><HEAD><TITLE>Result</TITLE></HEAD>
<BODY BGCOLOR=\"#FFAAAA\">
<H1>Hi there</H1><HR><BR>";
$i = 0;
while ($i <= $#ar) {
$ar[$i] =~ s/\+/ /g;
# заменяем в элементах массива + на пробел
$output .= "$ar[$i]\n";
# конкатенация переменной $output с
# элементом массива
$i++; }
$output .="<HR></BODY></HTML>";
# завершаем HTML страницу
print $output;
}
eval &Print;
# выполняем подпрограмму осуществляющую
# считывание, обработку и вывод информации
В данном примере был проиллюстрирован случай считывания параметров из входного
потока.
Если параметры передаются CGI-модулю в командной строке, то они помещаются в служебный
массив @ARGV. Например, если параметры пишуться в URL: http://www.host.ru/cgi-bin/name.cgi?123+resource+time+12 .
Для взаимодействия с файлами этого формата существует специальный модуль - Xbase.pm
На текущий момент поддерживается только возможность чтения таких файлов.
Этот модуль подключается стандартным образом: use Xbase;
Новый Xbase объект создается следующим образом:
$database = new Xbase;Будет создан объект
$database, который в дальнейшем будет использоваться для
взаимодействия со всевозможными методами, которые поддерживает модуль.
Доступ к базе данных осуществляется следующим образом:
$database->open_dbf($dbf_name,$idx_name);Мы ассоциировали DBF-файл и необязательный индексный файл с объектом. Чтобы определить тип (database type) можно сделать следующее:
print $database->dbf_type;Вернется строка, которая, если
Xbase файл открыт, будет содержать значение
DBF3, DBF4 или FOX.
Чтобы узнать дату последнего обновления делается следующее:
print $database->last_update;Возвращает строку с датой.
$end=$database->lastrec;Вернется номер последней записи в файле с базой данных.
$database->dbf_stat;В стандартный выходной поток будет напечатана информация о статусе и структуре базы данных. Этот метод работает аналогично команде
display status.idx_stat:
$database->idx_stat;Печатает в стандартный выходной поток (STDOUT) информацию о статусе открытого IDX-файла.
go_top:
$database->go_top;Передвигает курсор чтения на физическое начало файла,если индексы не существуют и на первую запись, соответствующую порядку, который задается индексом, в противоположном случае.
go_bottom:
$database->go_bottom;Передвигает курсор чтения на физический конец файла,если индексы не существуют и на последнюю запись, соответствующую порядку, который задается индексом, в противоположном случае.
go_next:
$database->go_next;Эквивалентно команде
skip 1, которая передвигает курсор на следующую запись.go_prev:
$database->go_prev;Эквивалентно команде
skip -1, которая передвигает курсор на предыдущую запись.$stat=$database->seek($keyvalue);Эта команда устанавливает курсор на первую запись, соответствующую данному ключу. Но в данном случае база данных должна быть открыта с соответствующим индексом, в противоположном случае будет выдано сообщение об ошибке и исполнение прекратиться. Возвращается значение, содержащее информацию о том, был ключ найден или нет.
$current_rec=$database->recno;Метод
bof возвращает значение true, если курсор находится в самом начале файла.
if ($database->bof) {
print " At the very top of the file \n";
}
Аналогично действует метод eof:
if ($database->eof) {
print " At the very end of the file \n";
}
Чтобы прочитать содержимое какого-либо поля записи можно поступить так:
print $database->get_field("NAME");
Возвращает строку с содержимым поля. Если данная запись помечена для удаления, то
использует псевдоимя поля _DELETED.@fields = $database->get_record;В массиве они будут располагаться в такой же последовательности, как и в базе данных.
close_dbf.
$database->close_dbf;Закрывает файл с базой данных, индексами и комментариями. В завершение приведем небольшой пример программы, которая распечатывает статус базы данных и индексного файла, а также дату последнего обновления и количество записей в базе данных.
#!/usr/bin/perl use Xbase; # подключение модуля $database = new Xbase; # создание объекта $d = "/home/smit/employee.dbf"; # имя файла с базой $i = "/home/smit/employee.cdx"; # имя индексного файла $database->open_dbf($d,$i); # открываем базу данных $database->dbf_stat; # печатаем статус и структуру # базы данных $database->idx_stat; # печатаем статус и структуру # индексов @fields = $database->get_record; print @fields,"\n"; # печатаем содержимое текущей записи print $database->last_update, "\n"; # печатаем дату последнего обновления $end = $database->lastrec; print $end; #печатаем номер последней записи
Полная спецификация языка Perl приводиться в Приложении 2 к отчету.
7.1 Введение
7.3 Состав
7.4 Установка
7.5 Использование
7.6 Спецификация процедур пакета htp
В данной главе отчета описывается свободно - распространяемое программное обеспечение - пакет WOW. Для освоения этого материала необходимо знание языка SQL и его процедурного расширения PL/SQL от фирмы Oracle. Кроме этого необходимо знание основ администрирования сервера Oracle. Информацию по PL/SQL Вы можете получить из документации по серверу Oracle, книга "PL/SQL Users Guide and Reference". Информацию об основах администрирования сервера Oracle можно получить из этой же документации, книга "Oracle7 Server Administration Guide".
Пакет WOW предназначен для использования под ОС Unix.
Пакет WOW предназначен для обработки запросов от WWW - сервера (Web -) к SQL - серверу Oracle (-Oracle-) с генерацией динамических HTML - документов (-Web). Разработчик приложений, использующий WOW оперирует только с родным языком Oracle - PL/SQL, являющимся процедурным расширением языка SQL. Это обуславливает высокую эффективность разработки приложений. Обработка созданных приложений непосредственно в сервере Oracle определяет высокую скорость исполнения приложений.
Основная идея пакета WOW - преобразование запроса к WWW - серверу в вызов определенной процедуры PL/SQL. В качестве параметров процедуры, используются данные из запроса к WWW - серверу. Кроме этого, язык PL/SQL дополняется функциями вывода различных данных в формате HTML. Сфера технологических решений пакета приведена на рис. 7-1.

Структурно, WOW состоит из ряда исполняемых программ, соответствующих спецификации CGI и набора пакетов PL/SQL (см. рис. 7-2).

Пакет htp содержит процедуры и функции, облегчающие формирование HTML - документа. Пакет htf содержит описание различных констант и функций, используемых при формировании HTML - документов.
Для корректной работы пакета необходимо правильно провести процедуру установки. Пакет WOW требует около 2Mb дискового пространства. На базовом сервере должны быть установлены:
В случае, когда пакет поставляется в виде исходных текстов, необходимо произвести компиляцию и сборку исполняемого модуля wowstub. При сборке wowstub необходимо использовать библиотеки установленного сервера Oracle или сетевого стека SQL*Net. Компиляция и сборка производится утилитой make на основании данных файла Makefile. Вам необходимо изменить ряд параметров Makefile для настройки на Вашу конфигурацию Oracle и Unix:
Независимо от сборки wowstub, необходимо создать ряд структур данных в БД Oracle.
Необходимо поместить модуль wowstub в каталог CGI программ Вашего WWW сервера. Необходимо переопределить ряд параметров файла wow, представляющего собой скрипт sh:
В случае если Вы используете версию от ЦНИТ НГУ, необходимо отредактировать все 4 файла: wow.win, wow.iso, wow.alt, wow.koi8.
Отредактированный файл wow (все 4 отредактированных файлы при использовании версии от ЦНИТ НГУ) необходимо поместить в каталог для CGI - программ Вашего WWW сервера.
Рассмотрим простейший пример с использованием пакета WOW. При обращении к WWW - серверу www.cnit.nsu.ru по URL:
http://www.cnit.nsu.ru/cgi-bin/wow.win/example.test?answer=no
происходит следующая цепочка действий (см. рис. 7-3):

URL, обращающийся к процедуре PL/SQL должен быть построен по определенным правилам и содержать ряд элементов:
Например:
http://www.cnit.nsu.ru/cgi-bin/wow.win
http://www.cnit.nsu.ru/cgi-bin/wow.win/test
Если процедура входит в состав пакета (example), созданного в схеме www, необходимо добавить имя пакета и имя процедуры:
http://www.cnit.nsu.ru/cgi-bin/wow.win/example.test
Когда пакет создан в другой схеме Oracle, необходимо указывать и имя схемы. Например, для схемы fancy получим:
http://www.cnit.nsu.ru/cgi-bin/wow.win/fancy.example.test
Пользователь www должен иметь права на исполнение этой процедуры, явно предоставленные оператором GRANT языка SQL.
<название_параметра> = <значение_параметра>
между собой, различные параметры разделяются амперсандом '&':
<название_параметра1>=<значение_параметра1>&<название_параметра2>= <значение_параметра2>
Название параметра должно совпадать с названием параметра вызываемой процедуры. Число параметров должно в точности соответствовать числу параметров процедуры. Если хотя бы одно из этих требований не соблюдено, Вы получите сообщение об ошибке. Порядок указания параметров значения не имеет. Большие и маленькие буквы в названии параметров равнозначны.
Число реально передаваемых параметров может и не совпадать с числом параметров, указанных в спецификации процедуры. В этом случае, все опускаемые параметры должны иметь значения по умолчанию.
Пример:
http://www.cnit.nsu.ru/cgi-bin/wow.win/example.test?answer=no
Исходя из описанного механизма работы пакета WOW можно сформулировать основные требования к PL/SQL - процедурам, обрабатывающим запросы от WWW - сервера.
Пример пакета example:
Create or Replace package example is
procedure test(answer in Varchar2);
end;
/
Create or Replace package body example
is
procedure test(answer in Varchar2) is
ответ varchar2(3);
cursor c_man(ans in varchar2) is select
Фамилия from Результаты_опроса where Ответ=ans order by Фамилия;
begin
-- Начало документа
htp.p('<HTML>');
-- Вывод названия страницы и заголовка
if answer = 'no'
then
ответ:='НЕТ';
htp.htitle('Фамилии людей, ответивших
отрицательно');
else
ответ:='ДА';
htp.htitle('Фамилии людей, ответивших
положительно');
end if;
htp.olistopen;
-- Начало нумерованного списка
for man in c_man(Ответ) loop
-- Элемент списка
htp.item(man.Фамилия);
end loop;
-- Конец нумерованного списка
htp.olistclose;
-- Конец документа
htp.p('</HTML>');
end;
end;
/
При этом подразумевается что в схеме WWW Oracle находится таблица примерно следующей структуры:
Create table Результаты_опроса(Фамилия
varchar2(30),
Имя varchar2(14),
Отчество varchar2(20),
Ответ varchar2(3));
Обращаться к пакету WOW можно и из форм HTML. Ниже приведен пример обращения к тому же пакету example из простейшей формы.
<HTML>
<HEAD>
<TITLE>Тестовая форма</TITLE>
</HEAD>
<BODY>
<H1>Тестовая форма</H1>
<FORM ACTION="http://www.cnit.nsu.ru/cgi-bin/wow.win/example.test">
Введите ответ:<INPUT NAME="answer">
<INPUT VALUE="Найти" TYPE="SUBMIT">
</FORM>
</BODY>
</HTML>
| procedure title(ctitle in varchar2) | - выводит название документа (теги <TITLE>) | ||||||||||||||||||||||||||||||||
| procedure htitle(ctitle in varchar2) | - выводит название документа и повторяет его в заголовке первого уровня (теги <TITLE>, <H1>) | ||||||||||||||||||||||||||||||||
| procedure header(nsize in integer, cheader in varchar2) | - выводит заголовок уровня nsize (теги <H1> ... <H6>) | ||||||||||||||||||||||||||||||||
| procedure url(curl in varchar2, cname in varchar2) | - формирует cname как гипертекстную связь, указывающую на curl (теги <A HREF>). | ||||||||||||||||||||||||||||||||
| procedure gif(curl in varchar2) | - включает в документ картинку, путь до которой curl (теги <IMG>). | ||||||||||||||||||||||||||||||||
| procedure gif(curl in varchar2, calign in varchar2) | - включает в документ картинку, путь до которой curl с выравниванием, определяемым параметром calign (теги <IMG>). | ||||||||||||||||||||||||||||||||
| procedure bold(ctext in varchar2) | - выводит текст ctext жирным шрифтом (теги <B>). | ||||||||||||||||||||||||||||||||
| procedure italic(ctext in varchar2) | - выводит текст ctext шрифтом italic (теги <I>) | ||||||||||||||||||||||||||||||||
| procedure item(cval in varchar2) | - выводит cval как элемент списка (теги <ITEM>). | ||||||||||||||||||||||||||||||||
| procedure formOpen(curl in varchar2) | - создает форму
с действием curl (теги <FORM>).
| ||||||||||||||||||||||||||||||||
| procedure formHidden(cname in varchar2, cvalue in varchar2) | - создает скрытое поле формы для хранения значения cvalue переменной с именем cname. | ||||||||||||||||||||||||||||||||
| procedure formPassword(cname in varchar2), procedure formPassword(cname in varchar2, cvalue in varchar2) | - создает поле формы для ввода значения переменной - пароля с именем cname и значением по умолчанию cvalue. | ||||||||||||||||||||||||||||||||
| procedure formField(cname in varchar2, nsize in integer), procedure formField(cname in varchar2), procedure formField(cname in varchar2, cvalue in varchar2) | - создает поле формы для ввода значения переменной с именем cname длиной nsize со значением по умолчанию cvalue. | ||||||||||||||||||||||||||||||||
| procedure formText(cname in varchar2, nrow in integer, ncol in integer) | - создает многострочное поле формы (длиной ncol, высотой nrow) для ввода значения переменной с именем cname. | ||||||||||||||||||||||||||||||||
| procedure formCheckbox(cname in varchar2) | - создает элемент checkbox для ввода значения логической переменной cname. | ||||||||||||||||||||||||||||||||
| procedure formRadio(cname in varchar2, cval in varchar2) | - создает элемент radiobutton для ввода одного из значений cval переменной cname. | ||||||||||||||||||||||||||||||||
| procedure formSelectOpen(cname in varchar2) | - создает список значений для переменной с именем cname. | ||||||||||||||||||||||||||||||||
| procedure formSelectOption(cval in varchar2) | - добавляет значение cval в список значений переменной, описанной в formSelectOpen. | ||||||||||||||||||||||||||||||||
| procedure formSelectClose | - заканчивает список значений, открытый formSelectOpen. | ||||||||||||||||||||||||||||||||
| procedure formDo(cname in varchar2) | - создает кнопку типа SUBMIT текущей формы с именем cname. | ||||||||||||||||||||||||||||||||
| procedure formDo | - создает кнопку типа SUBMIT текущей формы с именем 'Submit'. | ||||||||||||||||||||||||||||||||
| procedure formUndo(cname in varchar2) | - создает кнопку типа RESET текущей формы с именем cname. | ||||||||||||||||||||||||||||||||
| procedure formUndo | - создает кнопку типа RESET текущей формы с именем 'Reset'. | ||||||||||||||||||||||||||||||||
| procedure formClose | - закрывает текущую форму. | ||||||||||||||||||||||||||||||||
| Процедуры вывода: | |||||||||||||||||||||||||||||||||
| procedure print (cbuf in varchar2), procedure print (dbuf in date), procedure print (nbuf in number) | - выводят значение различных типов. | ||||||||||||||||||||||||||||||||
Синонимы для процедуры print
- p:
| procedure p (cbuf in varchar2), | procedure p (dbuf in date), procedure p (nbuf in number). |
Процедуры, выводящие постоянные
значения:
| procedure line | - разделительная
линия (тег <HR>).
| procedure para | - начало
параграфа (тег <P>).
| procedure nl | - перевод
строки (тег <BR>).
| procedure item | - элемент списка (тег <LI>).
| procedure ulistOpen |
- начало ненумерованного списка (тег <UL>).
| procedure ulistClose |
- окончание ненумерованного списка (тег </UL>).
| procedure olistOpen | -
начало нумерованного списка (тег <OL>).
| procedure olistClose |
- окончание нумерованного списка (тег </OL>).
| procedure dlistOpen |
- начало списка определений (тег <DL>).
| procedure dlistClose |
- окончание списка определений (тег </DL>).
| procedure dterm | - термин
списка определений (тег <DT>).
| procedure ddef | - определение
термина (тег <DD>).
| procedure preOpen | -
начало форматированного текста.
| procedure preClose | - окончание форматированного текста.
| | ||
PACKAGE phone IS
-- Главное меню
PROCEDURE MENU;
-- Список подразделений НГУ, если не определен параметр ID
-- Список абонентов подразделения НГУ, которое определяет ID
PROCEDURE SUBDIVISIONS(ID VARCHAR2 DEFAULT NULL);
-- Перечень букв алфавита на которые начинаются фамилии абонентов
PROCEDURE NAME;
-- Список абонентов, первая буква фамилии которых равна LETTER
PROCEDURE NAME(LETTER VARCHAR2);
-- Вся информация имеющаяся в БД об абоненте
PROCEDURE PERSON(ID VARCHAR2);
-- Выводит форму для ввода условия поиска
PROCEDURE QUERY;
-- Список абонентов, удовлетворяющий условию поиска по ФИО
PROCEDURE QUERY_NAME(LETTERS VARCHAR2 DEFAULT NULL);
END;
PACKAGE BODY phone IS
pkg VARCHAR2(100) := 'nsu.phone.'; --имя этого пакета
-- Заголовок HTML - документа
PROCEDURE HEADER(TT VARCHAR2) IS
BEGIN
htp.p('<HTML>');
htp.p('<HEAD>');
htp.p('<TITLE>'||TT||'</TITLE>');
htp.p('</HEAD>');
htp.p('<BODY BGCOLOR="#FFFFFF">');
htp.p('<TABLE WIDTH="100%" BGCOLOR="CCCCCC"><TR><TD ALIGN="CENTER"><B>Телефонный справочник НГУ</B></TABLE>');
htp.p('<P><P><P>');
END;
-- Конец HTML - документа
PROCEDURE FOOTER IS
BEGIN
htp.p('<P><P><P>');
htp.p('<CENTER>');
htp.p('<HR>');
htp.p('<FONT SIZE="-1">');
htp.p('Информация предоставлена Отделом Средств Связи НГУ.<BR>тел.39-71-00');
htp.p('<HR>');
htp.p('<EM>© <A HREF="mailto:zev@nsu.ru">Evgeny Zybarev</A>, 1996</EM>');
htp.p('</FONT>');
htp.p('</CENTER>');
htp.p('</BODY>');
htp.p('</HTML>');
END;
-- Вывод сообщения об ошибке
PROCEDURE sqlerror IS
BEGIN
HEADER('Ошибка!');
htp.p('<B>'||sqlerrm||'</B>');
FOOTER;
END;
-- Выводит список абонентов
-- Если PRM2 определено, то выбираются абоненты, работающие в подразделении
-- "1-го" уровня PRM и подразделении "2-го" уровня PRM2
-- Если PRM2 не определено, то выбираются абоненты,
-- чьи ФИО соответствую шаблону PRM
PROCEDURE PHONE_LIST(PRM VARCHAR2 DEFAULT '%', PRM2 VARCHAR2 DEFAULT NULL) IS
Cursor frm1 is
select Должность f1, ФИО f2, "Сл# телефон" f3, Место f4, ROWID
from TEL_SPIS
where upper(ПОДР) like upper(PRM) and
upper(ПОДРАЗДЕЛЕНИЕ) like upper(PRM2)
order by Должность;
Cursor frm2 is
select ФИО f2, "Сл# телефон" f3, Место f4, "Дом# телефон" f5, ROWID
from TEL_SPIS
where upper(ФИО) like upper(PRM)||'%'
order by ФИО;
ff VARCHAR2(100) := 'dummy';
FRM Number(1) := 1;
BEGIN
If PRM2 is not NULL Then FRM := 1; Else FRM := 2; End If;
htp.p('<TABLE WIDTH="100%" COLS="4" BORDERCOLOR="#CCCCCC">');
htp.p('<TR BGCOLOR="#CCCCCC">');
If FRM=1 Then htp.p('<TH>Должность или<BR>подразделение'); End If;
htp.p('<TH>Фамилия, имя, отчество');
htp.p('<TH>Телефон');
If FRM=2 Then htp.p('<TH>Домашний<BR>телефон'); End If;
htp.p('<TH>Номер комнаты<BR>и корпус');
If FRM=1 Then
For rec in frm1 Loop
htp.p('<TR ALIGN="LEFT">');
If ff!=rec.f1||rec.f2 Then
ff:=rec.f1||rec.f2;
htp.p('<TD>'||rec.f1);
htp.p('<TD><A HREF="'||pkg||'person?ID='||rec.ROWID||'">'||rec.f2||'</A>');
Else
htp.p('<TD><TD>');
End If;
htp.p('<TD ALIGN="CENTER">'||rec.f3);
htp.p('<TD ALIGN="CENTER">'||rec.f4);
End Loop;
ElsIf FRM=2 Then
For rec in frm2 Loop
htp.p('<TR ALIGN="LEFT">');
htp.p('<TD>');
If ff!=rec.f2 Then
ff:=rec.f2;
htp.p('<A HREF="'||pkg||'person?ID='||rec.ROWID||'">'||rec.f2||'</A>');
End If;
htp.p('<TD ALIGN="CENTER">'||rec.f3);
htp.p('<TD ALIGN="CENTER">'||rec.f5);
htp.p('<TD ALIGN="CENTER">'||rec.f4);
End Loop;
End If;
htp.p('</TABLE>');
END;
-- Главное меню
PROCEDURE MENU IS
BEGIN
HEADER('Телефонный справочник НГУ');
htp.p('<CENTER>');
htp.p('<TABLE BGCOLOR="#FFFFCC" WIDTH="50%" BORDER="1">');
htp.p('<TR ALIGN="CENTER">');
htp.p('<TD>');
htp.p('<A HREF="'||pkg||'subdivisions"><FONT SIZE="+2">Подразделения НГУ</FONT></A>');
htp.p('</TD>');
htp.p('</TR>');
htp.p('<TR ALIGN="CENTER">');
htp.p('<TD>');
htp.p('<A HREF="'||pkg||'name"><FONT SIZE="+2">Именной указатель</FONT></A>');
htp.p('</TD>');
htp.p('<TR ALIGN="CENTER">');
htp.p('<TD>');
htp.p('<A HREF="'||pkg||'query"><FONT SIZE="+2">Поиск по ФИО</FONT></A>');
htp.p('</TD>');
htp.p('</TR>');
htp.p('</TABLE>');
htp.p('</CENTER>');
FOOTER;
EXCEPTION WHEN OTHERS THEN sqlerror;
END;
-- Список подразделений НГУ, если не определен параметр ID
-- Список абонентов подразделения НГУ, которое определяет ID
PROCEDURE SUBDIVISIONS(ID VARCHAR2 DEFAULT NULL) IS
cursor sd is
select ПОДРАЗДЕЛЕНИЕ f1, max(ROWID) f2 from TEL_SPIS
group by ПОДРАЗДЕЛЕНИЕ order by 1;
BEGIN
HEADER('Телефонный справочник НГУ. Подразделения.');
If ID is NULL Then
htp.p('<CENTER><FONT SIZE="+1">Подразделения</FONT></CENTER>');
htp.p('<HR>');
htp.p('<UL>');
For rec in sd Loop
htp.p('<LI><A HREF="'||pkg||'subdivisions?ID='||rec.f2||'">'||rec.f1||'</A>');
End Loop;
htp.p('</UL>');
Else
Declare
pdr VarChar2(100);
Begin
For rec in (select ПОДРАЗДЕЛЕНИЕ f1 from TEL_SPIS where ROWID=ID) Loop
htp.p('<CENTER><FONT SIZE="+2"><B>'||rec.f1||'</B></FONT></CENTER>');
htp.p('<HR>');
pdr := rec.f1;
End Loop;
For rec in (select DISTINCT ПОДР f1 from TEL_SPIS
where ПОДРАЗДЕЛЕНИЕ=pdr and ПОДР=pdr order by 1)
Loop
PHONE_LIST(rec.f1,pdr);
End Loop;
For rec in (select DISTINCT ПОДР f1 from TEL_SPIS
where ПОДРАЗДЕЛЕНИЕ=pdr and ПОДР!=pdr order by 1)
Loop
htp.p('<HR>');
htp.p('<CENTER><FONT SIZE="+2">'||rec.f1||'</FONT></CENTER>');
htp.p('<HR>');
PHONE_LIST(rec.f1,pdr);
End Loop;
End;
End If;
FOOTER;
EXCEPTION WHEN OTHERS THEN sqlerror;
END;
-- Перечень букв алфавита на которые начинаются фамилии абонентов
PROCEDURE NAME IS
Cursor alf is select DISTINCT upper(substr(ФИО,1,1)) f1
from TEL_SPIS
where ФИО is not NULL
order by 1;
i Number := 0;
n Number := 10;
BEGIN
HEADER('Телефонный справочник НГУ. Именной указатель.');
htp.p('<CENTER>');
htp.p('<TABLE BORDER="1" CELLSPACING="3" CELLPADDING="3">');
htp.p('<CAPTION>');
htp.p('<HR WIDTH="300">');
htp.p('<FONT SIZE="+2">Именной указатель</FONT>');
htp.p('<HR WIDTH="300">');
htp.p('</CAPTION>');
htp.p('<TR BGCOLOR="#CCCCCC" ALIGN="CENTER">');
For rec in alf Loop
If i=n Then
htp.p('<TR BGCOLOR="#CCCCCC" ALIGN="CENTER">');
i:=0;
End If;
i := i+1;
htp.p('<TD>');
htp.p('<FONT SIZE="+2">');
htp.p('<A HREF="'||pkg||'name?LETTER='||to_char(ascii(rec.f1))||'">'||rec.f1||'</A>');
htp.p('</FONT>');
End Loop;
For j in i+1..n Loop
htp.p('<TD> ');
End Loop;
htp.p('</TABLE>');
htp.p('</CENTER>');
FOOTER;
EXCEPTION WHEN OTHERS THEN sqlerror;
END;
-- Список абонентов, первая буква фамилии которых равна LETTER
PROCEDURE NAME(LETTER VARCHAR2) IS
ff VARCHAR2(100):='dummy';
BEGIN
HEADER('Телефонный справочник НГУ. Именной указатель. '||LETTER);
htp.p('<CENTER>');
htp.p('<FONT SIZE="+1">Именной указатель</FONT>');
htp.p('<BR><FONT SIZE="+5">= '||chr(LETTER)||' =</FONT>');
htp.p('</CENTER>');
PHONE_LIST(chr(LETTER));
FOOTER;
EXCEPTION WHEN OTHERS THEN sqlerror;
END;
-- Вся информация имеющаяся в БД об абоненте
PROCEDURE PERSON(ID VARCHAR2) IS
cursor fio is select ФИО f1 from TEL_SPIS where ROWID=ID;
cursor prs(fio VARCHAR2) is
select ПОДРАЗДЕЛЕНИЕ f1, ПОДР f2, ДОЛЖНОСТЬ f3, МЕСТО f4, "Сл# телефон" f5
from TEL_SPIS where ФИО=fio order by 1,2;
cursor zv(fio VARCHAR2) is
select distinct ЗВАНИЕ f1 from TEL_SPIS where ФИО=fio;
cursor dt(fio VARCHAR2) is
select distinct "Дом# телефон" f1 from TEL_SPIS
where ФИО=fio and "Дом# телефон" is not NULL;
ff VARCHAR2(100);
f1 VARCHAR2(100) := 'dummy';
f2 VARCHAR2(100) := 'dummy';
f3 VARCHAR2(100) := 'dummy';
f4 VARCHAR2(100) := 'dummy';
BEGIN
open fio; fetch fio into ff; close fio;
HEADER('Телефонный справочник НГУ. '||ff);
htp.p('<TABLE WIDTH="100%" CELLPADDING="0" CELLSPACING="0">');
htp.p('<TR><TD ALIGN="CENTER"><FONT SIZE="+3">'||ff||'</FONT>');
htp.p('<TR><TD ALIGN="CENTER">');
For rec in zv(ff) Loop
If zv%ROWCOUNT>1 Then htp.p(', '); End If;
htp.p(rec.f1);
End Loop;
htp.p('</TABLE>');
htp.p('<CENTER>');
For rec in prs(ff) Loop
If f1!=rec.f1 Then
htp.p('<HR>');
f1:=rec.f1;
htp.p('<FONT SIZE="+2"><B>'||rec.f1||'</B></FONT>');
End If;
If f2!=rec.f2 and rec.f2!=rec.f1 Then
f2:=rec.f2;
htp.p('<BR><FONT SIZE="+1">'||rec.f2||'</FONT>');
End If;
If f3!=rec.f3 Then f3:=rec.f3; htp.p('<BR>'||rec.f3); End If;
If f4!=rec.f4 Then
f4:=rec.f4;
htp.p('<BR>'||rec.f4||'<BR>');
Else
htp.p('<BR>');
End If;
htp.p('<FONT SIZE="+2">'||rec.f5||'</FONT>');
End Loop;
For rec in dt(ff) Loop
If dt%ROWCOUNT=1 Then
htp.p('<HR>Дом.тел.: ');
Else
htp.p(', ');
End If;
htp.p(rec.f1);
End Loop;
htp.p('</CENTER>');
FOOTER;
EXCEPTION WHEN OTHERS THEN sqlerror;
END;
-- Выводит форму для ввода условия поиска
PROCEDURE QUERY IS
BEGIN
HEADER('Телефонный справочник НГУ. Поиск.');
htp.p('<CENTER>');
htp.p('<FONT SIZE="+2">Поиск</FONT>');
htp.p('<HR>');
htp.p('<FORM ACTION="'||pkg||'query_name" METHOD="POST">');
htp.p('ФИО : <INPUT TYPE="TEXT" NAME="LETTERS" SIZE="30">');
htp.p('<INPUT TYPE="SUBMIT" VALUE="Выполнить">');
htp.p('<FORM>');
htp.p('</CENTER>');
htp.p('<HR>');
htp.p('<BR>В качестве условия запроса можно задать первые буквы фамилии или шаблон :');
htp.p('<DL>');
htp.p('<DD> _ (подчерк) - заменяет любой символ');
htp.p('<DD> % (процент) - заменяет произвольную последовательность символов');
htp.p('</DL>');
htp.p('<BR><B>Например:</B> "% Сергей С_востьянович"');
FOOTER;
EXCEPTION WHEN OTHERS THEN sqlerror;
END;
-- Список абонентов, удовлетворяющий условию поиска по ФИО
PROCEDURE QUERY_NAME(LETTERS VARCHAR2 DEFAULT NULL) IS
BEGIN
HEADER('Телефонный справочник НГУ. Поиск по ФИО. '||LETTERS);
htp.p('<CENTER>');
htp.p('<FONT SIZE="+2">Результат поиска по ФИО</FONT><BR>');
htp.p('<FONT SIZE="+1">("'||LETTERS||'")</FONT>');
htp.p('</CENTER>');
If LETTERS is NULL Then
htp.p('<H1>Не задано условие для запроса!</H1>');
Else
PHONE_LIST(LETTERS);
End If;
FOOTER;
EXCEPTION WHEN OTHERS THEN sqlerror;
END;
END;
П1.1Графика и WWW
П1.1.1Вставка иллюстраций в HTML-документы
П1.1.2Особенности WWW-графики
П1.1.3Рекомендуемые графические программные пакеты
П1.1.3.1Программные пакеты для MS Windows 3.x, MS Windows 95 и MS Windows NT
П1.1.3.2Программные пакеты для ОС UNIX
П1.1.3.3Программные пакеты для Apple Macintosh
П1.1.4Основные типы графики для WWW
П1.1.5Как сделать так, чтобы изображения были гладкими?
П1.1.6Что такое transparent/interlaced GIFs и как их делать
П1.1.7Что такое progressive JPEGs и как ИХ делать
П1.1.8WWW и анимация
П1.2Стилевое оформление документов-трюки и советы
П1.2.1Хороший и плохой стили
П1.2.2Обзор различных программ просмотра
П1.2.3Тестирование страниц
П1.2.4Оптимизация Web-страниц
П1.2.4.1Текст
П1.2.4.2Графические изображения
П1.2.4.3Multimedia-материалы
П1.3Редакторы HTML
П1.4Программы преобразования форматов
Своей популярностью сеть World Wide Web отчасти обязана именно возможности графического оформления документов. Практически все современные браузеры (кроме тех, которые работают в алфавитно-цифровом режиме) в той или иной мере умеют отображать графику в различных форматах. Наиболее распространенным форматом для передачи графики по сети по сей день является формат GIF (Graphics Interchange Format), разработанный фирмой CompuServe, предоставляющей on-line сервис. Тому есть несколько причин: хороший коэффициент сжатия изображения, что очень заметно при передаче по сети, возможность создания ``постепенно проявляющихся'' (interlaced) изображений, простая анимация. Тем не менее, формату GIF присущи некоторые ограничения. Прежде всего, ограничение на количество цветов в изображении. Изображения в файлах формата GIF не могут иметь более 256 уникальных цветов. Раньше, когда устройства отображения, способные отображать большее количество цветов не были широко доступны, проблема эта не стояла так остро. Теперь же, когда такие устройства стали массовыми (большинство современных видеоадаптеров способно отображать как минимум 32768 цветов), ограничение это стало ощущаться очень сильно. В связи с этим, другим популярным форматом представления графики для WWW стал формат JPEG (Joint Photographic Expert Group), разработанный группой экспертов по фотографии, и ориентированный прежде всего, на хранение изображений фотографического качества, и соответственно, содержащих очень большое количество цветов. Основным недостатком (и, в то же время, достоинством) формата JPEG является то, что при сжатии происходит ПОТЕРЯ ИНФОРМАЦИИ. При этом достигается очень большой коэффициент сжатия (что очень важно при передаче по медленным каналам связи), но теряются некоторые детали изображения. В случае фотографических изображений это практически незаметно, но при попытке сжать в формат JPEG изображения, содержащие текст или схемы, потеря качества становится очень ощутимой. Кроме выбора формата, при подготовке графики для WWW следует обращать внимание на размеры растра изображений, выбор палитры и т.д.
Для вставки изображений в документ служит тег <IMG>. Это пустой тег, следовательно, закрывающего тега для него не существует. У тега есть несколько параметров:
SRC - обязательный параметр, указывающий URL файла с изображением.
ALT - рекомендуемый параметр, строка, заменяющая изображение при загрузке и в браузерах без поддержки графики.
WIDTH, HEIGHT - рекомендуемые параметры, горизонтальный размер растра изображения. При загрузке изображения браузер может отображать на его месте в документе рамку соответствующего размера.
BORDER - толщина рамки вокруг изображения, если изображение является частью активной зоны ссылки. Если BORDER=0, то рамка не будет отображаться.
HSPACE, VSPACE - позволяют задать свободное пространство вокруг изображения.
ALIGN - (TOP или BOTTOM или MIDDLE) положение текста относительно изображения. (LEFT или RIGHT) Положение изображения относительно окна браузера.
USEMAP - указывает, что изображение имеет активные зоны, описанные с помощью тега MAP в самом документе.
ISMAP - указывает, что изображение имеет активные зоны, и информацию о координатах выбранной точки следует передавать серверу.
При подготовке графического материала для WWW следует учитывать некоторую специфику, связанную с тем, что графика будет передаваться по сети, а также с тем, что он будет, в основном, отображаться на компьютерных дисплеях.
Еще одной особенностью является тот исторически сложившийся факт, что на графических системах с глубиной цвета 8 бит (256 цветов) используется фиксированная палитра из 216-ти цветов выбранных так, чтобы в палитре равномерно присутствовали цвета спектра.
При подготовке графических материалов для WWW можно применять любые программы, однако некоторые графические пакеты особенно для этих целей удобны либо имеют уникальные свойства, облегчающие работу Web-иллюстраторам.
Основная масса дизайнеров, работающих в среде MS Windows, предпочитает Adobe Photoshop как средство создания и обработки растровых изображений. Кроме ставших уже легендарными фильтров и подключаемых модулей, Photoshop умеет устранять зазубренности для всех основных примитивов, поддерживает большое количество графических форматов.
Для создания эффектов с форматом GIF лучше всего подходит программа Gif Construction Set for Windows (GIFCON) компании Alchemy Mindworks. С ее помощью можно делать с GIF-файлами практически все что угодно! На примере GIFCON можно понять, что даже для MS Windows бывают по настоящему хорошие программы.
Настоящим хитом является пакет CorelXARA компании Corel (Рис. П1.1.1). Этот пакет использует не растровую, а векторную графику, так же, как и известный шедевр той же компании под названием CorelDRAW!. В отличие от CorelDRAW!, CorelXARA ориентирован именно на Web-дизайнеров. Он умеет устранять зазубренности, имеет множество средств для деформирования. Обладает уникальной возможностью компоновки растровых и векторных данных, позволяя создавать потрясающие эффекты. Последние версии пакета умеют даже создавать анимированные GIF-файлы.
Для работы с трехмерной графикой очень удобно использовать такие профессиональные (и сложные в изучении) пакеты, как Autodesk 3D Studio и 3D Studio MAX, равно как и более простые пакеты вроде Caligari trueSpace. Компания Caligari (http://www.caligari.com) предлагает также комплект средств для создания трехмерных сцен в формате VRML (Virtual Reality Modelling Language).
Очень полезной при работе с изображениями в формате GIF оказывается программа gifblast, работающая в среде MSDOS и различных UNIX. Она оптимизирует GIF-файлы, уменьшая их байтовый размер. Уменьшение размера происходит из-за того, что многие производители программ, работающих с файлами в формате GIF, плохо оптимизируют свои продукты.
Для некоторых версий ОС UNIX, таких как SUN Solaris или SGI IRIX существуют версии пакета Adobe Photoshop. Кроме того, в Internet бесплатно доступно несколько бесплатных пакетов для работы с графикой: General Image Manipulating Package (GIMP), XPaint, и т.д. К сожалению, они по своим возможностям пока не сравнимы с коммерческими пакетами для ОС UNIX и MS Windows.
Платформа Apple Macintosh издавна славилась своей ориентированностью на графику и настольные издательства. Пользователям доступны пакеты Adobe Photoshop и Adobe Freehand, а также многие другие. К сожалению, автор не имел возможности испытать графические программы для Mac, поэтому список остается неполным.
Несмотря на то, что графическое оформление Web-страницы является довольно широким полем для фантазии, существует несколько типов наиболее употребимых графических вставок, как то:
В Internet имеются довольно обширные коллекции бесплатных изображений такого типа. Тем не менее, иногда бывает проще нарисовать их для конкретных страниц самостоятельно.
При внимательном рассмотрении растровых изображений становится заметным эффект зазубренности на наклонных прямых и дугах. Такой эффект, происходящий из-за дискретности устройств вывода, сильно портит впечатление от картинок. Взгляните на рисунок П1.1.2. Вы видите, как отличаются буквы?
Для устранения этого неприятного явления применяется довольно простой метод: в местах образования зазубренности вставляются точки промежуточных цветов. Этот метод называется anti-aliasing и реализован в абсолютном большинстве современных графических пакетов. Настоятельно рекомендуется применять его, если зазубренности на изображении сильно заметны, например, всегда включайте anti-aliasing для текста размером более 12-ти пунктов.
Графический формат GIF имеет несколько интересных возможностей, делающих его особенно привлекательным для WWW. К ним относятся возможности создавать ``прозрачные'' (transparent) изображения и изображения, проявляющиеся постепенно, по мере подкачки (interlaced). Эффект постепенного проявления достигается за счет черезстрочной отрисовки изображения: сначала появляются каждые четвертые строчки растра, затем каждые четвертые строчки со сдвигом на одну строку вниз и т.д. Таким образом, картинка появляется как бы в четыре приема. Эффект прозрачности состоит в том, что один из индексов палитры объявляется прозрачным, то есть при отображении вместо соответствующего цвета будет использоваться цвет ``из-под'' изображения, например, цвет фона документа.
Существует множество различных программ для большинства систем, позволяющих придать GIF-картинкам свойства прозрачности и черезстрочности. Из них выделяются по своим возможностям и удобству использования:
Существует возможность создавать GIF-файлы, которые отображаются черезстрочным способом. Эта возможность является очень удобной для Web-страниц. Не все знают, что подобная возможность имеется и в формате JPEG. Метод этот называется progressive JPEGs. Сейчас все большее количество программных пакетов начинает его использовать. Например для Adobe Photoshop существует подключаемый модуль, создающий progressive JPEGs. Смотрите внимательно в меню экспорта графики Вашей любимой программы. Быть может она уже имеет такую функцию!
Существует несколько способов ``оживления'' WWW-документов с помощью анимации, из которых наиболее употребительными являются так называемые ``анимированные GIF- файлы'' и программы на языке Java.
Спецификация формата GIF от 1989-го года позволяет хранить в одном файле несколько изображений и задавать порядок их отображения. На этом свойстве строится механизм, называемый ``animated-GIFs'', позволяющий ``оживить'' статические WWW-страницы. Последние версии таких браузеров, как Netscape Navigator и Microsoft Internet Explorer корректно отображают анимированные GIF-файлы. Фирмы-производители этих браузеров даже предоставляют небольшие анимированные рекламные изображения для тех, кто желает отметить на своих страницах, что они оптимизированы для просмотра в их браузерах.
Для создания анимированных GIF-файлов на платформе MS Windows можно применять ранее упоминавшуюся программу Gif Construction Set for Windows. Последние версии многих иллюстративных пакетов (например, CorelXARA) имеют встроенные возможности для создания анимаций в GIF-файлах.
За годы существования WWW выработалось множество рекомендаций относительно ``хорошего стиля'' Web-документов. Большое количество информации доступно по ссылкам с Web-сервера http://www.yahoo.com. Здесь приводится лишь краткий перечень правил, которые рекомендованы к использованию при создании Web-страниц.
~).
На сегодняшний день существует множество браузеров, как коммерческих, так и бесплатных. Все они имеют свои особенности, и очень важно их учитывать при создании Web-страниц.
Автору известны следующие браузеры для платформ Microsoft Windows и UNIX/XWindow:

К сожалению, образ мышления пользователей, общающихся с компьютерами от случая к случаю, сильно отличается от образа мышления профессиональных дизайнеров Web-страниц и программистов. По этой причине, зачастую, готовые и, вроде бы внешне очень привлекательные страницы не отвечают своему предназначению - доносить до пользователей информацию.
В связи с этим имеет смысл рассматривать Web-страницы как пользовательские
интерфейсы к данным, которые разработчики хотят донести до конечных
пользователей. А у хороших пользовательских интерфейсов есть очень
важные особенности: они ИНТУИТИВНО ПОНЯТНЫ и УДОБНЫ.
Под интуитивной понятностью можно в данном контексте понимать очевидность для
пользователя координат той информации, которую он хотел бы получить. Например,
если дизайнер разместил на картрированном изображения область
(картрированное изображение), за которой
скрывается какая-либо важная информация, но не выделил ее на изображении каким-либо
очевидным для пользователя образом (скажем, не оформил ее в виде очень
привлекательной для нажатия кнопки), можете быть уверены: никто до этой информации
не доберется.
Под удобством понимается количество трудозатрат пользователя по получению
какой-либо информации.
Именно для достижения максимального удобства пользователей следует
обращать большое внимание на тестирование
страниц перед их размещением в общедоступных местах.
Интересна методика разработки
и тестирования Web-страниц, применяемая в компании Sun Microsystems.
При создании больших WWW-документов очень важно распределить всю информацию между ветками иерархии страниц. К этому имеет смысл привлечь пользователей. В лаборатории Sun Microsystems, занимающейся разработкой Web-страниц, пользователям предлагается набор бумажных карточек с названиями материалов. Эти карточки пользователи раскладывают группами на столе в соответствии со своими представлениями. Понимая, что пользователям кажется идейно близким по содержанию, дизайнеры создают более удачные страницы.
После создания первых вариантов оформления страницы распечатываются на бумаге и демонстрируются пользователям. Предлагается угадать, что стоит за ссылками и рассказать общие впечатления от дизайна страниц. Если пользователям что-то не нравится, страницы приходится переделывать.
Последняя стадия тестирования заключается в демонстрации пользователям рабочего варианта страниц ``в рабочем виде''. Пользователь садится за компьютер с запущенным браузером и начинает ``путешествовать'' по новым страницам. Даются несколько заданий по поиску конкретной информации, а также наблюдается, на что пользователь больше всего обращает внимание.
По причине низкой пропускной способности каналов Internet возникает необходимость в жестком слежении за размерами элементов Web-страниц, особенно графики и multimedia-материалов. Для снижения размеров таких ресурсов существует несколько стандартных методик, но, вообще говоря, подход является индивидуальным. Каждое изображение или другой материал имеет свои особенности, и на них можно выиграть драгоценное снижение байтового размера. При разработке страницы на быстром компьютере и с высокоскоростным каналом связи не всегда заметно то, от чего страдают пользователи массовых модемов со скоростью 14400 бод (или даже ниже). Поставьте себе такой модем и посмотрите на создаваемые страницы! Если они плохо оптимизированы, то это откроет вам глаза. В этом разделе мы рассмотрим основные приемы, используемые при процессе оптимизации различных материалов для WWW.
Хотя текстовые файлы и занимают меньше всего места по сравнению с изображениями или звуком, определенную экономию можно извлечь и из них. Прежде всего -- комментарии в HTML-коде. Вы действительно уверены что все они необходимы? И уверены ли вы, что все то, что вставил в создаваемый документ ваш любимый редактор HTML, действительно нужно? Иногда оказывается, что нет. В таких случаях лишнее лучше убрать. Кроме того, лишнее присутствует даже во всех без исключения простых текстовых файлах формата DOS или Windows. Это лишнее содержится в конце каждой строки. Дело в том, что в системах семейства UNIX для указания перевода строки используется один символ, тогда как в системах DOS и Windows -- целых два. То есть, файл занимает на столько больше байт, чем может, сколько строк в нем содержится. Если ваш WWW сервер работает под управлением одной из разновидностей UNIX, попробуйте убрать лишнее из HTML файлов. Обычно это делается с помощью утилит типа fromdos, dos2unix, dtox, или им подобных (это зависит от типа используемой операционной системы). Спросите у вашего системного администратора. Он должен знать. Если он не знает, скажите об этом его начальнику. В любом случае, ВАМ это полезно знать, и вы имеете на это право!
Графические вставки являются наиболее объемными элементами обычных Web-страниц. По этой причине большинство приемов оптимизации ориентировано именно на изображения. В WWW используются (в основном) два типа форматов хранения графики: GIF(Graphics Interchange Format) и JPEG(Joint Photographic Experts Group). Оба они имеют свои достоинства и недостатки и имеют немного различные области применения. Формат GIF имеет ограничение на количество одновременно используемых в одном изображении цветов, их не может быть больше 256. При этом достигается довольно неплохой коэффициент сжатия без потерь (то есть, упакованное изображение полностью соответствует оригиналу) так как используется алгоритм LZW, отчасти используемый во многих популярных программах сжатия данных (ZIP, ARJ, LHA). Формат JPEG всегда использует так называемую ``полную'' цветовую модель, позволяя иметь в одном изображении очень много цветов (а именно - до ). Обычно такая обширная цветовая гамма необходима для хранения цифровых фотографий. Однако при таком великолепии цветов формат имеет один ``недостаток'', одновременно являющийся его достоинством: использование алгоритма сжатия с потерями. Это означает, что при упаковке изображение будет ИЗМЕНЕНО для достижения нужного коэффициента сжатия. На фотографиях такие изменения, связанные с устранением избыточной информации, почти не воспринимаемой глазом, почти не заметны, тогда как схему или график алгоритм может просто изувечить. Тем не менее, при хранении многоцветных изображений типа фотографий формат является предпочтительным, так как обеспечивает очень высокую степень сжатия.
Таким образом мы пришли к основополагающему моменту оптимизации размера - выбору формата хранения данных. Как уже говорилось выше, если нужна точность сохранения каждого пиксела (точки изображения) и ограничение на количество цветов не так уж важно, используйте формат GIF. Если же необходимо иметь в изображении больше чем 256 цветов, не используя никаких технологий смешивания, придется остановиться на формате JPEG, обеспечив с помощью подбора коэффициента сжатия оптимальное соотношение качества и байтового размера. Итак, первое правило:
Правильно выбирайте формат хранения изображения.
Помните, чем больше цветов имеет изображение, тем больше оно занимает места.
Очень часто при сохранении даже очень простых картинок в формате GIF выбирается
палитра из 256 цветов (8 битов на точку). Это не всегда оправдано, так как
иногда изображение содержит гораздо меньше цветов и может быть сохранено
с гораздо более низким цветовым разрешением (количеством бит на точку).
Например, если в изображении используется, скажем, 50 цветов, оно может быть
сохранено с палитрой в 64 цвета (6 битов на точку). Это может стоить
почти 30-ти процентной экономии размера! К сожалению, этот трюк не применим
к изображениям в формате JPEG, так как этот формат всегда использует
полную цветовую модель.
Итак, второе правило:
Сохраняйте изображения с цветовым разрешением, соответствующим количеству
цветов.
Труднее всего алгоритмам сжатия даются плавные цветовые переходы (у плавных
цветовых переходов имеются также и другие недостатки). Посему старайтесь
ими не злоупотреблять, если этого можно избежать. Кроме того, существует
проблема ограничения числа одновременно отображаемых цветов на устройствах
вывода (не у всех есть супер-гипер-термоядерные графические адаптеры с 16-ю
мегабайтами видеопамяти и ускорителями трехмерной графики!). То, что на одних
системах выглядит не миллион долларов, может повергнуть пользователей
старых добрых 256-ти цветных систем в состояние мрачного уныния.
Проверяйте вновь созданные Web-страницы на как можно более широком спектре
систем с различными возможностями.
Третье правило:
Избегайте сложных цветовых эффектов, они могут вызвать сильный рост
объема получаемых файлов.
Не все графические пакеты сами хорошо оптимизированы. Этот факт хорошо
иллюстрируется тем, что сохраняемые GIF-файли все еще имеют в себе избыток
информации. Окончательно ``выжать'' из них все лишнее (например, устранить
неоптимальности сжатия и устранить комментарии) помогают специальные
утилиты. Одной из таких утилит является свободно распространяемая
программа giflite для системы DOS. Она поистине творит чудеса, уменьшая
GIF-файлы на 10-50 процентов, не изменяя при этом хранящихся в них
изображений. Аналогом этой программы для систем семейства UNIX является
утилита gifblast (свободно распространяется в исходных текстах).
Обе эти программы можно найти на многих крупных FTP-серверах (воспользуйтесь
системой archie или одной из крупных поисковых систем по свободному
программному обеспечению вроде Shareware.com
или Jumbo.
Полученное нами четвертое правило гласит:
Используйте программы оптимизации GIF-файлов, они могут творить чудеса!
Всем известен способ делать GIF-файлы постепенно появляющимися (interlaced),
что позволяет достичь эффекта ускорения загрузки. Но далеко не все знают,
что при этом файлы становятся больше...Этот печальный факт вызван принципом
работы алгоритма LZW, используемого в формате GIF. Дело в том, что при
кодировании черезстрочного изображения строки его обрабатываются в порядки их
последующего отображения, то есть: первая, четвертая, седьмая и т.д. Это
эквивалентно сжатию другого изображения, состоящего из тех же строк, что и
исходное, только в другом порядке. Представьте, что оно из себя представляет!
Изображение становится сложнее с точки зрения наличия повторяющихся элементов.
Следствие -- увеличение размера.
Таким образом, Пятое правило говорит нам:
Не потеряйте желаемого эффекта ускорения загрузки, используя interlaced
GIF-файлы. Они могут намного сильно больше, чем раньше.
В последних версиях Netscape Navigator появился новый параметр тега <IMG>
под названием LOWSRC, который позволяет задать изображение низкого цветового
разрешения (обычно и вовсе черно-белое), которое должно быстро передаваться
и отображаться в то время, пока настоящее изображение (обычно большого размера)
подкачивается браузером. Не обманывайтесь! Добавляя в вашу страницу еще одно
изображение, вы только увеличите ее объем. Лучше сделайте более информативную
запись в параметре ALT тега <IMG>.
Шестое правило:
Параметр LOWSRC -- не спасение от медленных каналов связи а,
скорее, наоборот.
Иногда приходится вставлять в документ однотонное изображение, вроде
одноцветной разделительной полосы. При этом можно очень сильно сэкономить
в размерах, используя параметры WIDTH и HEIGHT тега <IMG>. Если указать
в них размеры, отличающиеся от реальных размеров растра изображения,
то изображение будет смасштабировано (увеличено или уменьшено) до указанных
размеров. Естественно, что сложные картинки при этом сильно испортятся, тогда
как простые однотонные вовсе не пострадают. Таким образом, можно создать
совсем небольшое изображение и, указав нужные размеры, достичь необходимого
эффекта с гораздо меньшими затратами.
Седьмое правило будет таким:
Используя параметры WIDTH и HEIGHT тега <IMG>, можно масштабировать изображения, экономя, таким образом, на размерах.
Все большее количество Web-страниц использует различные multimedia-материалы, как-то звуки или видеовставки. Они обычно имеют ОЧЕНЬ большой размер и передаются по сети ОЧЕНЬ долго. Как этого избежать? Единого ответа на этот вопрос нет. Все зависит от того что вам на самом деле нужно. Как всегда, возникает вопрос о форматах хранения данных. Для звука используются форматы MIDI, WAV (Windows Audio), AU (Sun Audio), AIFF (Mac Audio). Для видео-вставок -- AVI (Microsoft Video for Windows), MPEG (Motion Picture Experts Group), и MOV (Apple QuickTime movies). Рассмотрим сначала форматы хранения аудиоданных:
MIDI - Musical Instruments Digital Interface -- формат хранения команд для различных электронных музыкальных инструментов (например, синтезатора на музыкальной карте компьютера). Грубо говоря, внутри файла формата MIDI хранится нотная запись музыкального фрагмента. Это позволяет достичь минимального размера файла при максимальной сложности мелодии. Файлы MIDI являются оптимальными для записи мелодий, если не требуется гарантий абсолютно идентичного звучания различных инструментов на различных системах.
WAV - формат хранения звуков, используемый в системах семейства Windows. Содержит запись звука в виде сигнала, то есть, гарантирует точность воспроизведения (если, конечно, устройство вывода позволяет).
AU - формат представления звука, используемый в системах компании Sun Microsystems. По принципу схож с WAV. Имеет встроенную компрессию.
AIFF - формат представления аудиоданных, используемый в системах Apple Computer и Silicon Graphics. По принципу схож с WAV. Имеет встроенную компрессию.
Как и в случае с изображениями, следует прежде всего избавиться от избыточной
информации. Для цифрового звука характерны два параметра, влияющие на размер
данных: частота оцифровки и разрядность уровня сигнала. Частота оцифровки
определяет, сколько раз в секунду замерялся уровень сигнала (и сколько раз в
секунду он будет меняться при нормальном воспроизведении). Разрядность
показывает, сколько бит при этом выделялось на запись этого уровня.
Для примера: на музыкальных компакт-дисках частота дискретизации составляет
примерно 44.1 Кгерц при разрядности 16 бит. Нетрудно подсчитать, что при
такой схеме одна секунда звука будет занимать больше 88 килобайт (!)
К счастью, уровень качества звука, присущий компакт-дискам, далеко не всегда
необходим при передаче звука по сетям. Например, для корректной передачи
голоса достаточно частоты дискретизации в 8.0 Кгерц при разрядности
сигнала в 8 бит. Таким образом, в те же 88 килобайт поместится уже почти
11 секунд звучания голоса. Если при этом использовать еще и сжатие (с потерями),
то это значение можно сильно увеличить.
Таким образом, главное правило звучит так:
Для звуковых файлов выбирайте минимальную частоту дискретизации и
разрядность, при которых качество все еще остается приемлемым. Выбирайте формат
с максимальным показателем сжатия для ваших данных.
Видеовставки, пожалуй -- самый объемный элемент современных Web-страниц.
Единственный совет, который можно дать по отношению к ним: старайтесь не
вставлять их прямо в документ (inline). Лучше вставьте один из кадров
в виде статичной картинки и сделайте ссылку на весь фрагмент. Кроме того,
можно выбирать формат и способ компрессии, достигая при этом оптимального
соотношения размер / качество.
Обычно в WWW применяются следующие форматы хранения видеофрагментов:
AVI - формат компании Microsoft, используемый в системах семейства Windows. Построен по схеме применения так называемых ``кодеков'', то есть модулей сжатия/распаковки. Точно такой же подход используется в формате QuickTime фирмы Apple, только набор стандартных кодеков отличается.
QuickTime MOV - формат, разработанный компанией Apple и ныне получивший повсеместное распространение. Программы его воспроизведения (некоторое множество кодеков) ныне существуют для большинства систем.
MPEG - Формат экспертной группы по кинематографии. Очень сильно распространен и популярен.
Хотя все без исключения HTML-документы могут быть созданы при помощи простого текстового редактора, в настоящее время широко используются различные специализированные программы для редактирования документов для Web.
Большинство существующих редакторов HTML представляет собой простые ASCII-редакторы, дополненные возможностями, облегчающими жизнь создателям Web-документов, например, диалоговыми окнами вставки изображений. К таким редакторам относятся программы Webber, DarekWare HTML Author для системы Windows, asWedit, xHTML для UNIX и другие.
Вторая категория, называемая ``полу-WYSIWYG'' (What You See Is What You Get), включает программы, обеспечивающие просмотр конечного вида документа по мере его подготовки. При этом документ отображается встроенным браузером редактора в дополнительном окне. К этой категории относится, например, WebEdit для Windows.
Третья и самая популярная среди начинающих Web-дизайнеров категория -- полные-WYSIWYG редакторы. Они обеспечивают полное (максимальное) приближение внешнего вида редактируемого документа к его конечному виду в браузере. При этом пользователю совершенно не нужно разбираться в тегах языка HTML. Очень часто такие редакторы встраиваются непосредственно в Web-браузеры. Примеры:
У разных подходов есть различные преимущества и недостатки. Знатоки и ценители системы LaTeX никогда не будут использовать WYSIWYG-редакторы для подготовки своих страниц, также как и многие опытные разработчики документов для Web. Дело в том, что за внешней простотой и красотой визуальных средств разработки скрывается некоторая недостаточность в функциональных возможностях и неоправданная избыточность информации, добавляемой редактором в документ. Кроме того, теряется контроль над использованием расширений.
Автор считает разумной достаточностью использование опытными пользователями редакторов принадлежащих к первой категории, так как присущий им сервис еще не перешел ту невидимую черту, когда он еще не кажется навязчивым. Для тех же, кто интенсивно работает в Microsoft Word, лучшим решением будет, несомненно, являться Microsoft Internet Assistant for Word.
Для многих популярных форматов данных существуют программы преобразования в HTML, позволяющие быстро и эффективно публиковать в Internet уже существующую информацию, не прибегая к медленному процессу ручного преобразования. Хорошим примером такого типа программ может служить серия Microsoft Internet Assistants для всех программ, входящих в пакет Microsoft Office. Microsoft Internet Assistant for Word мы уже рассматривали ранее (см. главу про редакторы HTML). Поиск конвертеров из нужного формата оставляется читателям в качестве упражнения на использование Web-браузера.
Для обозначения цветов можно использовать слова вроде красный или белый. Но человеческий глаз различает миллионы цветовых оттенков, и не хватит слов ни одного языка, чтобы точно передать каждый из них. По этой причине с приближением эры цветного телевидения и печати люди стали задумываться над тем, как можно закодировать информацию о цвете.
Всем хорошо известно, что существует чистые цвета (цвета видимого спектра, радуги) и смешанные цвета (например, белый цвет -- смешанный). В видимом спектре четко выделяются три основных цветовых оттенка: красный, зеленый и синий. Было замечено, что, смешивая эти основные цвета, можно с хорошей точностью получать почти все возможные оттенки, наблюдаемые нами в спектре. Именно на принципе смешения красного, зеленого и синего цветов построены электронные лучевые трубки цветных телевизоров и мониторов.
Как известно, компьютеры работают с числами, и именно с числами им проще всего работать. Естественно, что для обозначения яркости цветовых компонент (так мы будем называть интенсивности основных цветов) в цифровой технике стали применять числа. Подсчитано, что для корректного цветовоспроизведения достаточно выделить по 256 уровней интенсивности для каждой из компонент. За нулевой уровень принимается полное отсутствие яркости, за 255-й -- полная яркость. Таким образом может быть отображено цветов. Для короткого обозначения такого представления цветов используется аббревиатура RGB (от Red-Green-Blue, названий основных цветов на английском языке). Если представить себе цветовое пространство, соответствующее RGB-модели, то оно будет представлять собой куб в системе координат, где в качестве осей выбраны линии возрастания интенсивности компонент, точками которого будут являться конкретные цвета. Люди с хорошим пространственным воображением, представив себе такой куб, могут сразу примерно прикидывать RGB-разложения конкретных цветов. RGB-куб выглядит примерно так:
Запись RGB-описания цвета удобно производить в виде так называемого RGB-триплета: тройки чисел в шестнадцатеричной системе счисления (тогда все числа будут двузначными). Шестнадцатеричная система счисления отличается от общепринятой десятичной тем, что в качестве основания при разложении чисел используется число 16. ``Дополнительными'' цифрами считаются шесть первых букв латинского алфавита: A, B, C, D, E, F. Для получения RGB-триплета из имеющихся десятичных значений компонент легко произвести с помощью научного калькулятора (если не настоящего, то содержащегося в системе MS Windows или аналогичного).
Получить значения RGB-компонент какого-либо конкретного цвета можно с помощью некотроых графических пакетов: диалоговые окна выбора цветов нередко содержат подобную информацию. Хорошим примером программы, имеющей подобные возможности, служит великолепный пакет Paint Shop Pro компании Jasc Inc. Если вы не хотите даже иметь дело с ``ученой цифирью'', вам сильно поможет программа Color Manipulation Device, доступная в Internet. Для пользователей системы XWindow можно порекомендовать программы XColorMix и XColorSel, также доступные в Internet.
| - | 	 | Горизонтальная табуляция | |
| - | | Перевод строки | |
| - | | Возврат каретки | |
|   | Пробел | ||
| ^ | ^ | Крышка | |
| _ | _ | Подчерк | |
| ` | ` | Мягкое ударение | |
| { | { | Левая фигурная скобка | |
| | | Вертикальная черта | ||
| } | } | Правая фигурная скобка | |
~ | ~ | Тильда | |
|   | Неразрывный пробел | | |
| ¡ | ¡ | Перевернутый восклицательный знак | |
| c | ¢ | Значок цента | |
| £ | £ | Фунт стерлингов | |
| Y | ¥ | Йена | |
| § | § | Параграф | |
| ¨ | ¨ | Умляут (dieresis) | |
| © | © | Символ копирайта | © |
| « | Левая кириллическая кавычка | ||
| ¬ | Значок отрицания | ||
| - | ­ | Дефис | |
| R | ® | Зарегистрированная торговая марка | |
| ¯ | ¯ | Акцент (Macron accent) | |
| ° | Градус | ||
| ± | Плюс-минус | ||
| ² | Квадрат | ||
| ³ | Куб | ||
| ´ | ´ | Акцент (Accute accent) | |
| µ | Микро (мю) | ||
| ¶ | ¶ | Абзац | |
| · | |||
| ¸ | ¸ | Цедилла | |
| ¹ | Первая степень | ||
| » | Правая кириллическая кавычка | ||
| 1/4 | ¼ | Четверть | |
| 1/2 | ½ | Половина | |
| 3/4 | ¾ | Три четверти | |
| ¿ | ¿ | Перевернутый знак вопроса | |
| À | À | A с акцентом (grave) | À |
| Á | Á | A с акцентом (acute) | Á |
| Â | Â | A с акцентом (circumflex) | Â |
| Ã | Ã | A с акцентом (tilde) | Ã |
| Ä | Ä | A с акцентом (umlaut) | Ä |
| Å | Å | Ангстрем | Å |
| Æ | Æ | Æдифтонг | Æ |
| Ç | Ç | Заглавная C с цедиллой | Ç |
| È | È | Заглавное E с акцентом (grave) | È |
| É | É | Заглавное E с акцентом (acute) | É |
| Ê | Ê | Заглавное E с акцентом (circumflex) | Ê |
| Ë | Ë | Заглавное E с акцентом (umlaut) | Ë |
| Ì | Ì | Заглавное I с акцентом (grave) | Ì |
| Í | Í | Заглавное I с акцентом (acute) | Í |
| Î | Î | Заглавное I с акцентом (circumflex) | Î |
| Ï | Ï | Заглавное I с акцентом (umlaut) | Ï |
| Ñ | Ñ | Заглавное N с акцентом (tilde) | Ñ |
| Ò | Ò | Заглавное O с акцентом (grave) | Ò |
| Ó | Ó | Заглавное O с акцентом (acute) | Ó |
| Ô | Ô | Заглавное O с акцентом (circumflex) | Ô |
| Õ | Õ | Заглавное O с акцентом (tilde) | Õ |
| Ö | Ö | Заглавное O с акцентом (umlaut) | Ö |
| × | Умножение | ||
| Ø | Ø | Заглавное O с акцентом (slash) | Ø |
| Ù | Ù | Заглавное O с акцентом (grave) | Ù |
| Ú | Ú | Заглавное U с акцентом (acute) | Ú |
| Û | Û | Заглавное U с акцентом (circumflex) | Û |
| Ũ | Ü | Заглавное U с акцентом (tilde) | Ũ |
| Ý | Ý | Заглавное Y с акцентом (acute) | Ý |
| ß | ß | Малое острое s (sz ligature) | &sz; |
| à | à | a с акцентом (grave) | à |
| á | á | a с акцентом (acute) | á |
| â | â | a с акцентом (circumflex) | â |
| ã | ã | a с акцентом (tilde) | ã |
| ä | ä | a с акцентом (umlaut) | ¨ |
| å | å | a с акцентом (ring) | å |
| æ | æ | æ(ae ligature) | æ |
| ç | ç | c с акцентом (цедилла) | ç |
| è | è | e с акцентом (grave) | è |
| é | é | e с акцентом (acute) | é |
| ê | ê | e с акцентом (circumflex) | ê |
| ë | ë | e с акцентом (umlaut) | ë |
| ì | ì | i с акцентом (grave) | ì |
| í | í | i с акцентом (acute) | í |
| î | î | i с акцентом (circumflex) | î |
| ï | ï | i с акцентом (umlaut) | ï |
| ñ | ñ | n с акцентом (tilde) | ñ |
| ò | ò | o с акцентом (grave) | ò |
| ó | ó | o с акцентом (acute) | ó |
| ô | ô | o с акцентом (circumflex) | ô |
| õ | õ | o с акцентом (tilde) | õ |
| ö | ö | o с акцентом (umlaut) | ö |
| ÷ | Деление | ||
| ø | ø | o с акцентом (slash) | ø |
| ù | ù | u с акцентом (grave) | ù |
| ú | ú | u с акцентом (acute) | ú |
| û | û | u с акцентом (circumflex) | û |
| ü | ü | u с акцентом (umlaut) | ü |
| ý | ý | y с акцентом (acute) | ý |
| ÿ | ÿ | y с акцентом (umlaut) | ÿ |
П2.1Основные особенности Perl
П2.1.1Введение
П2.2Cтруктуры данных
П2.2.1Скалярные величины
П2.2.2Простые массивы
П2.2.3Ассоциативные массивы
П2.3Синтаксис языка Perl
П2.3.1Основные понятия
П2.3.2Простые операторы
П2.3.3Составные операторы
П2.3.4Операторы языка Perl
П2.3.4.1Термы и операторы списка
П2.3.4.2Оператор ``стрелка''
П2.3.4.3Операторы ++ и - -
П2.3.4.4Экспоненциальный оператор
П2.3.4.5Символьные унарные операторы
П2.3.4.6Операторы связки
П2.3.4.7Бинарные операторы
П2.3.4.8Операторы сдвига
П2.3.4.9Операторы сравнения
П2.3.4.10Операторы эквивалентности
П2.3.4.11Побитовое И, побитовое ИЛИ и Исключающее ИЛИ
П2.3.4.12Логическое И и логическое ИЛИ
П2.3.4.13Оператор диапазона
П2.3.4.14Условный оператор
П2.3.4.15Операторы присваивания
П2.3.4.16Оператор ``запятая''
П2.3.4.17Логическое НЕ
П2.3.4.18Логическое И, ИЛИ и Исключающее ИЛИ
П2.3.4.19Оператор чтения из файла
П2.3.4.20Оператор замены строки
П2.3.4.21Оператор замены множества символов
П2.4Языковые конструкции Perl
П2.4.1Ссылки
П2.4.1.1Основные понятия
П2.4.1.2Символьные ссылки
П2.4.2Регулярные выражения
П2.4.3Зарезервированные переменные
П2.4.4Встроенные функции
П2.4.5Подпрограммы и модули
П2.4.5.1Подпрограммы
П2.4.5.2Пакеты
П2.4.5.3Таблицы символов
П2.4.5.4Конструкторы и деструкторы пакетов
П2.4.5.5Классы
П2.4.5.6Модули
П2.5Объектная ориентация
П2.5.1Объекты
П2.5.2Классы
П2.5.3Методы
П2.5.4Вызов метода
П2.5.5Деструкторы
Perl - интерпретируемый язык, приспособленный для обработки произвольных
текстовых файлов, извлечения из них необходимой информациии и выдачи сообщений.
Perl также удобен для написания различных системных программ. Этот язык прост
в использовании, эффективен, но про него трудно сказать, что он элегантен и
компактен. Perl сочитает в себе лучшие черты C, shell, sed и awk,
поэтому для тех, кто знаком с ними, изучение Perl-а не представляет
особого труда.
Cинтаксис выражений Perl-а близок к синтаксису C. В отличие от большинства
утилит ОС UNIX Perl не ставит ограничений на объем обрабатываемых данных и если
хватает ресурсов, то весь файл обрабатывается как одна строка. Рекурсия может
быть произвольной глубины. Хотя Perl приспособлен для сканирования текстовых
файлов, он может обрабатывать так же двоичные данные и создавать .dbm файлы,
подобные ассоциативным массивам. Perl позволяет использовать регулярные
выражения, создавать объекты, вставлять в программу на С или C++ куски
кода на Perl-е, а также позволяет осуществлять доступ к базам данных, в том числе
Oracle.
Ниже приводится в качестве примера небольшая программа, которая осуществляет доступ к
Oracle.
#! /usr/local/bin/perl -w
# запуск с ключом печати ошибок.
use Oraperl;
# подключение модуля для работы с Oracle
$system_id = 'T:bdhost.somwere.com:Base';
# описание имени базы данных
$lda = &ora_login($system_id, 'scott','tiger');
# подключение к базе данных пользователя
# scott с паролем tiger
$statement = 'create table MYTABLE
(NAME char(10), TITLE char(20),
ORGANIZATION varchar2(256))';
# SQL команда создания таблицы MYTABLE
$csr = &ora_open($lda, $statement)
|| die $ora_errstr;
# открытие курсора csr, если это невозможно,
# то осуществляется выход и печать сообщения об ошибке.
&ora_close($csr); # закрытие курсора
open(FL, '/home/my_home_directory/my_file')
|| die "Can't open file \n";
# открытие файла, если это невозможно,
# то выход с печатью сообщения об ошибке
while ($string = <FL>) {
# чтение входного потока из файла с дескриптором FL
@array = split(/\//,$string);
# считанная строка разбивается в массив
# строк, разделителем служит слеш
$st = 'insert into MYTABLE values(:1,:2,:3)';
# SQL команда помещения в таблицу некоторых значений
$csr = &ora_open($lda,$st) || $ora_errstr;
# открытие курсора или печать
# сообщения об ошибке и выход
&ora_bind($csr,$array[0],$array[1],$array[2]);
# привязка значений переменных к величинам, которые
# требуется поместить в таблицу
&ora_close($csr); # закрытие курсора
}
close FL; # закрытие файла
&ora_commit($lda);
# завершение транзакции в базе данных
&ora_logoff($lda);
# отключение от базы данных
Perl поддерживает три типа данных:
Обычные массивы, как и в языке C, индексируются числами, начиная с нуля.
Ассоциативные массивы индексируются строками.
Простые скаляры (в дальнейшем мы будем также называть их переменными) всегда
начинаются со знака доллара: $, даже в том случае, когда мы обращаемся к
элементу массива.
¯Простой массив начинается со знака$dayпростая переменнаяday$day[28]29 элемент массиваday$day{'Feb'}значение 'Feb' из хэша%day$#dayпоследний индекс массива@day
@:
¯Ассоциативный массив (хэш) начинается со знака процент@dayмассивday-($day[1],$day[2],...)@day[3,4,5]то же, что и@day[3..5]
%:%day (key1, val1, key2, val2, ...) FOO, foo и Foo будут
рассматриваться Perl-ом как разные переменные. Имена, начинающиеся с буквы или
знака подчеркивания, могут в дальнейшем содержать в себе цифры или знаки подчеркивания.
Имена,
начинающиеся с цифры, могут в дальнейшем содержать только цифры. Имена, начинающиеся не с буквы, цифры или подчерка должны состоять только из одного символа.
Большинство таких имен зарезервировано, например $$ является
идентификатором текущего процесса.
Интерпретация команды или величины часто зависит от требований контекста.
Существует два основных контекста: скалярный и списковый. Некоторые операции
возвращают список величин если в контексте подразумевается список и одну величину,
если контекст скалярный.
Например, операция &ora_fetch в скалярном контексте возвращает количество
выбранных строк:$nfields = &ora_fetch($csr);@array = &ora_fetch($csr);Скалярные переменные могут содержать различные простые типы данных, такие как
числа, строки или ссылки. Они не могут содержать сложные типы, но могут содержать
ссылку на массив или хэш. В булевском контексте скаляр принимает значение
TRUE, если он содержит не нулевое число или не пустую строку.
В Perl существует несколько способов записи чисел:
¯Строки заключаются в одинарные или двойные кавычки. Использование кавычек в Perl такое же как в1234512345.67.23E-100xffffшестнадцатеричная запись0377восьмеричная запись.1_234_567_890подчерк для удобства чтения.
bourne shell-е: строка в двойных кавычках
обрабатывается и вместо переменных подставляются их значения, а также
обрабатываются бакслэш-последовательности, строки в одинарных кавычках
рассматривается просто как последовательности символов. Используются также:
¯\tтабуляция\nперевод строки\rвозврат каретки\bпробел\eсимвол Escape\033восьмеричный формат\x1bшестнадцатеричный формат\c[управляющая последовательность (control)\aсигнал (alarm)\fпереход на следующую страницу
Perl позволяет произвольно удлинять массив путем обращения к элементу, индекс
которого больше, чем последний индекс массива. Так же можно произвольно
уменьшить длину массива.
@day = ('a','b');
$day[3] = 'c';
Теперь массив day содержит три элемента: ('a','b','c').
@day = (); или, что то же самое: $#day = -1;
Теперь массив day пуст.
(@day, @month, &SomeSub) содержит в себе элементы массива day, за ними
следуют элементы массива month, а за ними результат выполнения подпрограммы
SomeSub.
Пустой массив обозначается (). Массив ((),(),(),()) эквивалентен пустому
массиву. Последний элемент массива может быть массивом или хэшэм:
($a, $b, @c)= split;
($a, $b, %c)= @_;
Любой элемент массива может быть массивом.
Ассоциативные массивы или хэши содержат пары ``ключ'' и ``значение''. Например:
\%map = ('red',0x00f,'blue',0x0f0,'green',0xf00);
Часто для удобства чтения между ``ключом'' и ``значением'' ставят оператор =>.
%map = (
'red' => 0x00f,
'blue' => 0x0f0,
'green' => )xf00
);
Программа на Perl-е состоит из последовательности команд. В отличие от
типизированных языков Perl не требует объявления типов своих объектов. Все
объекты, определенные в программе, до присваивания им какого-либо значения по
умолчанию принимают значение ``0''. Последовательность команд исполняется сразу,
в отличие от sed и awk, где исполняется последовательно каждая строка.
Комментарии выделяются знаком #, и вся строка следующая за этим знаком
будет рассматриваться как комментарий.
Если вы написали подпрограмму, то ее можно вызывать только ниже по тексту
программы.
Блоком называется последовательность операторов, логически составляющая
единое целое в теле программы, как правило, блоки заключаются в фигурные
скобки.
Каждая команда отделяется от других точкой с запятой. Точка с запятой не обязательна,
только если оператор является последним в блоке.
Последовательность простых операторов может следовать за отдельным
модификатором. В Perl-е простыми модификаторами являются:
if (EXPR)
unless (EXPR)
while (EXPR)
until (EXPR)
В операторах while и until проверка условия происходит перед выполнением
тела блока, за исключением одного случая, когда используется do-оператор:
do {
$_ = <STDIN>;
...
} until $_ eq ".\n";
в котором проверка условия происходит после выполнения блока.
Операторы цикла, которые будут описаны далее, не будут работать в этой
конструкции, так как отсутствует метка цикла.
if (EXPR) BLOCK
if (EXPR) BLOCK else BLOCK
if (EXPR) BLOCK eslif (EXPR) BLOCK else BLOCK
LABEL: while (EXPR) BLOCK
LABEL: while (EXPR) BLOCK continue BLOCK
LABEL: for (EXPR; EXPR; EXPR;...) BLOCK
LABEL: foreach VAR(LIST) BLOCK
LABEL: BLOCK continue BLOCK
В отличие от C и Pascal все определяется в терминах блоков, а не операторов:
то есть фигурные скобки являются обязательными.
Метка состоит из идентификатора и двоеточия. Она ставится в начале цикла и
служит указателем для операторов цикла next, last и redo (их описание смотри
ниже). Если это continue блок, то он выполняется перед тем, как условие будет
проверено снова, как третья часть for оператора в C. Правильность условия
может зависеть от результатов выполнения блока, например:
$i = 1;
while ($i < 10){
...
} continue {
$i++;
}
или, что тоже самое:
for ($i = 1; $i < 10; $i++;) {
...
}
Foreach цикл присваивает переменной по очереди каждое значение из списка и выполняет над ней все команды из блока. Переменная является локальной и существует только в пределах данного цикла. Если список является массивом, то его
можно изменять в цикле, посредством операций над переменной. Если переменная
опускается, то по умолчанию в качестве нее используется $_.
foreach \$elem(@elements) \{\$elem = \$elem * 2;\}
-- цикл по всему содержимому
массива @items.
Пример:
for ((1,2,3,4,5,6,7,8,9,10,'boom')) {
print $_,"\n"; sleep(1); }
for (1..15) { print "Merry Christmas\n"; }
foreach $item (split(/[\/\*\\n]/,$ENV{'TERMCAP'})) {
print "Item: $item\n"; }
Блок семантически эквивалентен циклу, который исполняется один раз. Поэтому в
него можно включать операторы контроля цикла, чтобы выйти из него или запустить
его еще раз.
Операторы в Perl-е имеют различный приоритет. Операторы, заимствованные из C,
сохранили между собой ту же иерархию, что и в C. Термы имеют самый большой
приоритет, они содержат переменные, кавычки, выражения в скобках,
функции с их
параметрами. Если за списковым оператором ( например, print()) или унарным
оператором ( например, chdir()) следует список аргументов, заключенный в
скобки, то эта последовательность имеет самый высокий приоритет, подобно
функции с аргументами. Аналогично термам обрабатываются последовательности
do{} и eval{}.
Также, как в С и С++ ``->'' является инфиксным оператором ссылки. Если правая
часть является [...] или {...} подпрограммой, тогда левая часть должна быть
символьной ссылкой на массив или хэш. Если правая часть - это имя метода или
скалярная переменная содержащая имя метода, то левая часть должна быть объектом
или именем класса.
Эти операторы работают также как и в С. То есть, если они стоят перед
переменной, то они увеличивают или уменьшают переменную до возвращения значения.
Если они стоят после переменной, то увеличение или уменьшение переменной
происходит после возврата значения. Если переменная содержит в себе число или
употребляется в скалярном контексте, то использование ++ дает обычное
увеличение значения. Если же переменная употреблялась только в строковом
контексте, не является пустой строкой и содержит символы a-z,A-Z,0..9, то
происходит строковое увеличение значения переменной:
print ++($foo = '99'); - напечатает 100
print ++($foo = 'a0'); - напечатает a1
print ++($foo = 'Az'); - напечатает Ba
print ++($foo = 'zz'); - напечатает aaa
В Perl-е двойная звездочка ** является экспоненциальным оператором. Он
требует к себе даже больше внимания, чем унарный минус: -2**4 это -(2**4), но
не (-2)**4.
Унарный ! означает логическое отрицание. Унарный минус, в случае числового
значения переменной, обозначает обычное арифметическое отрицание. Если операндом
является идентификатор, то возвращается строка, состоящая из знака минус и
идентификатора. Если строка начинается со знака + или -, то возвращается
строка, начинающаяся с противоположного знака.
Унарная тильда ``~'' обозначает побитовое отрицание.
Унарный плюс не имеет влияния даже на строки. Он используется для отделения
имя функции от выражения заключенного в скобки, которое иначе рассматривается
как список аргументов.
rand (10) * 20; - (rand10) * 20; rand +(10) * 20; - rand(10 * 20);Унарный бэкслэш ``'' обозначает ссылку на то, что стоит за ним.
Знак равенства с тильдой ``=~''связывает выражение слева
с определенным шаблоном. Некоторые операторы обрабатывают и модифицируют
переменную $_. Эти же операции иногда желательно бывает выполнить над
другой переменной. Правый аргумент это образец поиска, подстановки или
трансляции, левый аргумент - это то, что должно быть подставлено вместо
$_. Возвращаемая величина показывает успех операции.
Бинарное ``!~'' это тоже самое, что и ``=~'', только
возвращаемая величина является отрицательной в логическом смысле.
Звездочка * - умножение двух чисел. Cлэш / - деление числа на число.
Процент % - вычисляет модуль двух чисел, x - оператор повторения. В
скалярном контексте возвращает строку, состоящую из многократно повторенного
левого операнда, причем повторяется он то количество раз, которое стоит справа.
В списковом контексте он многократно повторяет список.
print 'a' x 80; напечатает букву a 80 раз.
@ones = (1) x 80; массив из восьмидесяти единиц.
@ones = (5) x @ones сделает все элементы равными пяти.
Бинарный плюс - операция сложения двух чисел.
Бинарный минус - операция вычитания двух чисел.
Бинарная точка - конкатенация строк.
Двоичный сдвиг осуществляется, как и во многих других языках программирования, с помощью операторов ``<<'' и ``>>''. При применении этих операторов значения левых аргументов сдвигаются в соответствующую сторону на количество разрядов, указанное в правых аргументах. Аргументы должны быть целочисленными.
``<'' - возвращает TRUE если левый аргумент численно меньше, чем правый.
``>'' - возвращает TRUE если правый аргумент численно меньше, чем левый.
``<='' - возвращает TRUE если правый аргумент численно меньше или равен левому.
``>='' - возвращает TRUE если левый аргумент численно меньше или равен правому.
``gt'' - возвращает TRUE если левый аргумент меньше (в строковом контексте), чем правый.
``lt'' - возвращает TRUE если правый аргумент меньше (в строковом контексте), чем левый.
На поведение операторов lt и gt влияют установки
системного языка, если операционная система способна работать с несколькими
языками. По этой причине операторы должны корректно работать со строками
на языках, отличных от US ASCII, что в системе UNIX задается указанием
свойств LC_COLLATE системного locale.
== возвращает TRUE, если левый аргумент численно эквивалентен правому.
!= возвращает TRUE, если левый аргумент численно неэквивалентен правому.
<=> возвращает -1, 0 или 1 в зависимости от того, численно меньше,
равен или больше левый аргумент правого.
eq возвращает TRUE, если левый аргумент эквивалентен правому (в строковом контексте).
ne возвращает TRUE, если левый аргумент неэквивалентен правому (в строковом контексте).
cmp возвращает -1, 0 или 1 в зависимости от того, меньше равен или
больше левый аргумент правого (в строковом контексте).
Бинарное & возвращает объединенные побитово операнды.
Бинарное | возвращает перемноженные побитово операнды.
Бинарное ^ возвращает исключенные побитово операнды.
Бинарное && - логическое И. Если левый аргумент FALSE, то правый
не проверяется.
Бинарное || - логическое ИЛИ. Если левый аргумент TRUE, то правый
аргумент не проверяется.
||''и && отличаются от подобных операторов в \verbC| тем, что вместо 0 или
1 они возвращают последнюю обработанную величину.
Таким образом, наиболее удобным способом определить домашний каталог
пользователя из переменной окружения HOME будет (на практике такой способ
определения домашнего каталога пользователя не рекомендуется):
$home = $ENV{'HOME'} || $ENV{'LOGDIR'} ||
(getpwuid($<))[7] || die "You're homeless!\n";
В качестве более удобной для чтения альтернативы Perl поддерживает операторы and и
or, которые будут описаны далее. Их приоритет ниже, однако их можно с
удобством использовать, не расставляя скобки,
после операторов, аргументами которых являются списки:
unlink "alpha", "beta", "gamma"
or gripe(), next LINE;
Если писать в стиле C, то это может быть записано так:
unlink("alpha", "beta", "gamma")
|| (gripe(), next LINE);
.. - оператор диапазона. Реально это два разных оператора, в зависимости
от контекста. В списковом контексте он работает как оператор диапазона от
левого аргумента до правого.
for (1..10) {
#code
}
В скалярном контексте он возвращает булевское
значение. Если левый операнд TRUE, то .. принимает значение TRUE, если
правый операнд тоже TRUE.
if (101..200) { print 'hi;)';}
- напечатает вторую сотню строк
?: также как и в C является условным оператором. Он работает подобно
if-then-else. Если аргумент перед ? - TRUE, то возвращается аргумент
перед :,
в противоположном случае возвращается аргумент после :.
Скалярный или списковый контекст второго и третьего аргументов передается
по наследству.
($a_or_b ? $a : $b) = $c;
= - обычный оператор присваивания. Вообще операторы присваивания работают
также как и в C.
$a += 2; - то же самое, что и $a = $a + 2;
Можно использовать следующие сокращения:
**= += *= &= <<= &&=
-= /= |= >>= ||=
.= %= ^= x=
($a += 2) *= 3; - то же самое, что и :
$a = $a + 2;
$a = $a * 3;
, - оператор запятая или comma-оператор. В скалярном контексте он
обрабатывает левый аргумент и отбрасывает его значение, потом обрабатывает
правый аргумент и возвращает его величину. В этом он подобен comma-оператору
из C. В списковом контексте он играет роль разделителя аргументов и вставляет
оба аргумента в список. => является синонимом comma-оператора.
Унарное NOT возвращает отрицание аргумента. Оно эквивалентно !, за
исключением более низкого приоритета.
and возвращает конъюнкцию двух выражений. Он эквивалентен &&, за
исключением более низкого приоритета.
or возвращает дизъюнкцию аргументов. Он эквивалентен ||, за исключением
более низкого приоритета.
xor (eXclusive OR) - исключающее ИЛИ, возвращает истину, если истинен
ровно один из аргументов.
В Perl есть несколько операций ввода-вывода. Для вывода из файла используется команда <>.
open(STDIN,"/etc/passwd");
while ($string = <STDIN>)
{
@a = split(/[:]/,$string);
}
Внутри этих скобок стоит дескриптор файла. Считывание происходит построчно.
В конце файла <STDIN> принимает значение FALSE и цикл while завершается.
По умолчанию считывание происходит в переменную $_. Нулевой дескриптор файла
используется также как в sed и awk, то есть считывается поток из файлов перечисленных
в командной строке.
Оператор s/PATTERN/REPLACEMENT/egimosx производит поиск строки, соответствующей
шаблону PATTERN и если строка найдена, то подстановку на ее место текста
REPLACEMENT. Возвращает количество произведенных подстановок.
Если перед этим не использовался оператор =~ или !~ для определения
переменной, которая будет обрабатываться, то будет модифицироваться переменная $_.
Этот оператор используется со следующими опциями:
$path =~ s|/usr/local/bin|/usr/bin|; ($foo = $bar) =~ s/this/that/o; $count = ($paragraf =~ s/Mister\b/Mr./gm);
tr/SEARCHLIST/REPLACEMENTLIST/cds y/SEARCHLIST/REPLACEMENTLIST/cds
Заменяет все найденные символы из множества символов SEARCHLIST на
соответствующие символы из множества символов REPLACEMENTLIST. Возвращает
число символов, которые были заменены или удалены. Если посредством операторов
=~, !~ не была указана никакая строка, то обрабатывается переменная $_.
y является синонимом tr. Если SEARCHLIST заключен в скобки,
то REPLACEMENTLIST тоже заключается в скобки, которые могут отличаться от тех,
в которые заключается шаблон, например:
tr[A-Z][a-z] tr(+-*/)/ABCD/Этот оператор употребляется со следующими опциями:
SEARCHLIST на
REPLACEMENTLIST, например:
tr/a-zA-Z/ /cs;заменит неалфавитные символы.
$a = 'CCCCCCCCC'; $a =~ tr/C/D/s;теперь
$a = 'D'
В предыдущих версиях Perl была реализована возможность только символьных ссылок. Perl версии 5 и выше позволяет использовать не только символьные ссылки на переменные, но и ``жесткие'' ссылки на любые данные. Так как любой скаляр может быть ссылкой, а массивы и хэши состоят из скаляров, то можно с легкостью организовать массив массивов, массив хэшей, хэш массивов и так далее. ``Жесткие'' ссылки следят за счетчиком ссылки и как только счетчик становится равным нулю, автоматически удаляют ссылку. Символьные ссылки содержат только имя переменной, также как символьная ссылка файловой системы содержит просто имя файла. Ссылки могут быть созданы несколькими способами:
& - создается еще одна ссылка, так как одна уже
существует в символьной таблице.)
$varref = \$foo; $arref = @ARGV; $hashref = \%ENV; $coderef = \&handler;
$arrayref = [1,2,['a','b','c']];По адресу
$arrayref[2][1] будет храниться значение b.
$hashref = {
'Earth' => 'Moon',
'Jupiter' => 'Kallisto',
...
};
sub,
без определения имени подпрограммы:
$coderef = sub { print "Hello!\n" };
$bar = $$scalarref;
push(@$arrayref,$filename);
$$arrayref[0] = "January";
$$hashref{"key"} = "value";
&$coderef(1,2,3);
$refrefref = \\\"how are you?";
print $$$$refrefref;
- напечатает ``how are you?''.$в фигурные скобки. Приведенный пример тогда будет выглядеть таким
образом:
$bar = ${$scalarref};
push(@{$arrayref},$filename);
${$arrayref}[0] = "January";
${$hashref}{"key"} = "value";
&{$coderef}(1,2,3);
В данном случае использование фигурных скобок ничего не меняет, но в общем случае в
скобках может стоять произвольное выражение, даже подпрограмма:
&{ $dispatch{$index} }(1,2,3);
$arrayref->[0] = "January";
$hashref->{"key"} = "value";
Левая часть должна быть выражением, возвращающим ссылку, возможно также являющуимся
раскрытием ссылки:
$array[$x]->{"foo"}->[0] = "January";
ref() может быть использована для определения типа объекта, на который
указывает ссылка. Функция bless() может быть использована для ассоциирования
ссылки с пакетом, функционирующим как объектный класс.
Мы рассмотрели, что происходит, если величина, используемая в качестве ссылки, не была определена ранее. Что же происходит, если она уже определена и не является жесткой ссылкой? В таком случае она обрабатывается как символьная ссылка. То есть значение скаляра рассматривается как имя переменной, а не прямая ссылка на переменную.
¯$name = "foo";$$name = 1;- то же самое, что$foo = 1;${$name} = 2;- то же самое, что$foo = 2;${$name x 2 }= 3; -то же самое, что$foofoo = 3;$name->[0] = 4;-то же самое, что$foo[0] = 4;@$name = ();- обнуляет массив@foo&$name();- вызывает&foo
Perl позволяет использовать регулярные выражения.
Для того чтобы пояснить, что же представляет из себя регулярное выражение
приведем несколько примеров:
/SWAP.*/ - соответствуют все слова начинающиеся со SWAP и заканчивающихся
произвольным набором символов. Точка обозначает произвольный символ, звездочка -
то, что символ, стоящий перед ней, входит в слово 0 и более раз. Все метасимволы,
которые будут описаны ниже, бозначают вхождение того, что стоит перед ними.
/\w*/ - соответствуют слова состоящие только из алфавитных, цифровых
символов и символа подчерк. \w - соответствует алфавитным, цифровым
символам и символу подчерк, звездочка - тому, что эти символы могут входить
произволное количество раз.
Здесь мы приведем
только основные метасимволы. Для более подробной информации смотрите
соответствующие страницы man по Perl.
¯Метасимвол*соответствует 0 или более вхождений+соответствует 1 или более вхождений?соответствует 1 или 0 вхождений{n}соответствует ровно n вхождений{n,}соответствует по крайней мере n вхождений{n,m}соответствует по крайней мере n, но не более m вхождений
* эквивалентен {0,}, + эквивалентен
{1,} и ? эквивалентен {0,1}. Ограничений на величину m и n
нет. Эта стандартная конструкция работает в ``жадном'' режиме, то есть:
регулярному выражению a.*b будет соответствовать всевозможный набор слов начинающихся
с символа a и кончающихся символом b, в том числе слова типа abcab. В таких
словах есть подпоследовательности символов, которые также удовлетворяют условиям
регулярного выражения. Если после каждого из описанных метасимволов поставить знак
?, то подобные последовательности будут опускаться.
Шаблоны обрабатываются как строка в двойных кавычках, поэтому приведенные ниже
последовательности также будут обрабатываться:
¯А также все перечисленные ранее бакслэш-последовательности. В Perl-е определены также:\l- передвижение на символ вниз\u- передвижение на символ вверх
¯Обратите внимание, что\w- соответствуют алфавитные и цифровые символы а также символ подчерк\$W- соответствуют все символы не входящие во множество символов w\s- символы пробела, табуляции, возврата каретки\S- все символы не входящие во множество символов s\d- цифровые символы\D- нецифровые символы
\w отмечает только отдельные
символы, а не все слово. Чтобы отметить все слово нужно использовать \w+.
Также определены следующие команды:
¯При использовании конструкции типа ( ... ),\b- соответствуют границы слова\B- соответствуют не-границы слова\A- соответствуют только начало строки\Z- соответствуют только конец строки
\<digit> подставляет
подстроку из скобок с номером digit. Можно использовать скобки для
отделения подшаблона. Если в скобках имеется более, чем 9 подстрок, то
переменные $10, $11, ... содержат соответствующие подстроки.
$+ возвращает то, чему соответствует последняя конструкция в скобках. $&
возвращает подставленную строку. $` возвращает все перед подставленной
строкой, $' возвращает все после подставленной строки.
$_ = 'abcdefghi'; /def/; print "$`:$&:$'\n"; - напечатает abc:def:ghiНа этом мы закончим описание регулярных выражений, для более подробной информации читайте
manual page.
В Perl есть имена имеющие специальное значение. Многие из них аналогичны
зарезервированным именам в shell.
Если вы хотите использовать длинные имена
переменных, в заголовке программы требуется сказать:
use English;
Многие переменные доступны только для чтения, то есть при попытке присвоения
такой переменной какого-либо значения напрямую или по ссылке происходит ошибка.
$_ В эту переменную по умолчанию происходит ввод, присваивание, в нее складываются результаты поиска по заданному образцу.
while(<>){...}
или, что то же самое:
while($_= <>) {...}
$<digit>
Эта переменная была описана в предыдущем параграфе. Она
доступна только для чтения, так же как и переменные $&, $`, $' и $+.
$. Эта переменная содержит номер строки, которая была почитана последней из файла, который был прочитан последним. Она также доступна только для чтения.
$/
Содержит символ по которому разделяются вводимые записи. По умолчанию
содержит символ перевода строки. Она похожа на переменную RS из awk.
$| По умолчанию имеет значение 0. Если содержит ненулевое значение, то происходит сброс буферов каждый раз после осуществления вывода (на печать, на экран и т.д.).
$,
Содержит символ-разделитель полей для оператора печати. Подобна
переменной OFS в awk.
$
Содержит символ-разделитель записей для оператора печати.
Подобна переменной ORS в awk. (Вы можете определить $ вместо того,
чтобы печатать n в конце печати.)
$"
Подобна переменной $,. Но используется при обращении к списку величин
в двойных кавычках (или другой строке, которая требует интерпретации). По
умолчанию содержит символ пробел.
$;
Содержит символ-разделитель для эмуляции многомерных хэшей. Если
ссылаться на такой элемент хэша как $foo{$a,$b,$c} то реально это будет
происходить так: $foo{join($;,$a,$b,$c)}. Не путайте с @foo{$a,$b,$c},
так как это тоже самое, что($foo{$a},$foo{$b},$foo{$c}). По умолчанию
содержит значение \034 такое же как переменная SUBSEP в awk.
$#
Формат для печати чисел. Подобна переменной OFMT в awk. Первоначально
содержит значение %.20g.
$% Содержит номер текущей выводимой страницы.
$= Содержит длину текущей страницы (количество печатных срок), обычно содержит значение 60.
$- Содержит значение, определяющее количество оставшихся на странице строк, например количество еще не напечатанных строк для печатного канала вывода.
$~ Содержит имя текущего формата сообщений. Обычно имя дескриптора файла.
$^
Содержит имя текущего формата заголовка страницы. Обычно содержит имя
дескриптора файла с добавлением в конце _TOP
$: Содержит множество символов после которых вывод сроки может быть прерван и начат снова после перевода строки.
$! Если эта переменная используется в числовом контексте, то содержит текущее значение errno (номер ошибки) со всеми обычными сообщениями. В строковом контексте содержит соответствующее системное сообщение об ошибке.
$@
Содержит сообщение о синтаксической ошибке, допущенной во время
исполнения последней команды eval(). Если содержит значение 0, то команда
была исполнена корректно. Но заметьте, что сообщения не накапливаются в этой
переменной.
$$ Содержит идентификатор текущего процесса.
$< Содержит идентификатор пользователя (UID), которому принадлежит текущий процесс.
$> Содержит эффективный UID текущего процесса.
$( Содержит идентификатор группы (GID) пользователя, которому принадлежит текущий процесс.
$) Содержит эффективный GID текущего процесса.
$0 Содержит имя файла, в котором находится исполняемая программа.
$ARGV Содержит имя текущего файла, из которого происходит чтение.
@ARGV Содержит массив аргументов командной строки, которые были переданы программе.
@INC
Содержит список точек входа в программу, в которых используются
конструкции do EXPR, require и use.
%INC
Содержит входы для каждого файла, который включается посредством
использования операторов do или require. Ключами являются имена файлов, а значениями
места их расположения.
%ENV Содержит текущее окружение процесса. Изменением содержимого хэша можно изменить окружение порожденного (дочернего) процесса.
%SIG Этот хэш используется для установки обработчиков различных сигналов. Например:
sub handler {
local($sig) = @_;
print "Caught a SIG$sig - shutting down\n";
close(LOG);
exit(0);
}
$SIG{'INT'} = 'handler';
$SIG{'QUIT'} = 'handler';
...
$SIG{'INT'} = 'DEFAULT';
$SIG{'QUIT'} = 'IGNORE';
abs VALUE Возвращает абсолютное значение аргумента.
accept NEWSOCKET, GENERICSOCKET
подобно системному вызову accept(2) ждет соединения.
Возвращает запакованный адрес, если соединение произошло успешно и FALSE в
противоположном случае.
atan2 Y,X
Возвращает arctg(Y/X).
bind SOCKET, NAME
Привязывает сетевой адрес к сокету,
также как системный вызов bind в OS UNIX или любой другой
системе, поддерживающей BSD Sockets. Если привязка произошла
успешно, возвращает TRUE, в противном случае - FALSE. Переменная NAME должна
содержать запакованный адрес, соответствующего для сокета типа.
Тип адреса для разных видов сокетов определяется в терминах языка C структурой
sockaddr, которая представляет собой абстрактный тип, содержащий
все данные, необходимые для сокета.
binmode FILEHANDLE Позволяет читать или писать файл с соответствующим дескриптором в бинарном режиме.
bless REF, PACKAGE
Эта функция присоединяет объект на который указывает
ссылка REF, к пакету PACKAGE, если он определен, если же он опущен, то к текущему
пакету. Для удобства возвращает ссылку, так как bless() часто является последним
оператором в конструкторе.
caller EXPR
Возвращает контекст текущего вызова подпрограммы. В скалярном
контексте возвращает TRUE, если мы находимся внутри подпрограммы, eval() или
require(). FALSE в противоположном случае. В списковом контексте возвращает:
($package, $filename, $line) = caller;С аргументом
EXPR возвращает более сложную информацию, которая используется
отладчиком для печати карты стека. Значение EXPR отмечает глубину стека до
текущей записи.
($package, $filename, $line, $subroutine, $hasargs, $wantargs) = caller($i);
chdir EXPR
Изменяет текущую директорию на указанную в EXPR, если это
возможно. Если EXPR опущено, то устанавливает в качестве текущей директории
домашнюю директорию. Возвращает TRUE в случае успеха и FALSE иначе.
chmod LIST
Изменяет права доступа к файлам указанным в LIST. Первым
аргументом должна быть маска доступа в цифровом формате. Возвращает число
файлов права доступа к которым были успешно сменены.
$cnt = chmod 0700 'foo','bar'; chmod 700 @executables;
chown LIST Изменяет хозяина или группу, которой принадлежит список файлов. Первыми двумя аргументами должны быть uid и gid. Возвращает количество успешных изменений.
chr NUMBER
Возвращает символ, представленный номером NUMBER в наборе
символов. Например, chr(65) вернет A.
close FILEHANDLE
Закрывает файл с дескриптором FILEHANDLE. Для более подробной
информации читайте manual page.
open(OUTPUT '/usr/home/petrov'); ... close OUTPUT;
closedir DIRHANDLE
Закрывает каталог открытый вызовом opendir().
connect SOCKET,NAME
Пытается соединиться с удаленным сокетом (по аналогии с системным вызовом).
Возвращает TRUE в случае успешного соединения и FALSE в противоположном случае.
Переменная NAME должна содержать запакованный адрес соответствующего данному
сокету типа.
cos EXPR
Возвращает косинус EXPR, выраженного в радианах. Если EXPR опущено,
возвращает косинус $_.
dbmopen ASSOC, DBNAME, MODE
Связывает dbm(3) или ndbm(3) файл с
ассоциативным массивом. ASSOC - имя ассоциативного массива. DBNAME - имя базы данных
(без .dir или .pag расширения). Если база данных не существует, то она создается
с правами доступа указанными в MODE.
dbmopen(%HIST,'/usr/lib/news/history', 0600);
while (($key, $val) = each %HIST){
print $key, '=', unpack('L',$val),\n;}
dbmclose(%HIST);
dbmclose ASSOC Прерывает связь между файлом и ассоциативным массивом.
defined EXPR
Возвращает TRUE или FALSE, в зависимости от того определено
значение EXPR или нет. Многие операции возвращают неопределенное значение в
случае конца файла, неинициализированной переменной, системной ошибки или при
подобной ситуации. Если речь идет о хэше, то defined покажет только определены ли
ли величины, ничего не говоря о существовании ключей. Для определения существования
ключей используется функция exists().
delete EXPR Стирает указанную величину. Возвращает удаленную величину или значение не определено в случае, если удаление не произошло.
foreach $key (keys %array) {
delete $array{$key};
}
Но более быстро то же самое можно сделать используя функцию undef().
die LIST
Вне eval() печатает значение LIST в STDERR и выходит из программы с
текущим значением $!. Если значение $! есть ноль, то принимает значение $? >> 8.
Если значение $? >> 8 есть ноль, то принимает значение 255. Внутри eval()
сообщение об ошибке помещается в переменную $@ и eval() прерывается с
неопределенным значением.
open(FL, "/root/rm-rf") || die "Can't open file.\n";
do BLOCK Функцией не является. Возвращает значение последней операции внутри блока.
do EXPR
Использует величину EXPR как имя файла и далее запускает содержимое
этого файла, как программу на Perl. Обычно это используется для включения
библиотечных подпрограмм.
do 'stat.pl';Это то же самое, что:
eval 'cat stat.pl';Однако подключать библиотечные модули более удобно используя
use и require.
each ASSOC_ARRAY
Возвращает массив из двух элементов, содержащий ключ
и значение из хэша, причем по очереди перебирает все пары ($key, $value).
while (($key,$value) = each %ENV){
print " $key = $value \n";
}
eof FILEHANDLE
Возвращает 1, если следующее считывание возвращает конец
файла или если FILEHANDLE не был открыт. При опущении аргумента eof обрабатывает
последний файл, из которого происходило считывание. Но на практике эта функция
редко используется, так как в Perl-е операторы чтения возвращают неопределенное
значение в конце файла.
eval EXPR
EXPR выполняется как маленькая программа в контексте основной
программы. Определенные переменные и подпрограммы остаются определенными и в
дальнейшем. Возвращается значение, которое возникает при обработке последнего
выражения. Если EXPR опущено, то обрабатывается $_.
exec LIST
Исполняет внешнюю программу и НИКОГДА не возвращает управление.
На самом деле (в UNIX) производится системный вызов семейства exec, который
подменяет программу, исполняющуюся в рамках текущего процесса.
Если LIST представляет собой список из более, чем одного аргумента, то вызывается execvp(3)
с аргументами из LIST. Если аргумент только один, то он проверяется на метасимволы
shell. Если они присутствуют, то он далее передается /bin/sh -c для обработки.
Если же их нет, то аргумент передается напрямую execvp, который более эффективен.
exists EXPR
Возвращает TRUE, если в хэше есть ключи и даже в том случае,
когда значения VALUE не определены.
exit EXPR
Обрабатывает EXPR и осуществляет немедленный выход с полученной
величиной.
$ans = <STDIN>; exit 0 if $ans =~ /^[Xx]/;Если
EXPR опущено, то осуществляет выход с нулевым статусом.
exp EXPR
Возвращает е (основание натурального логарифма e = 2.718281828...)
в степени EXPR. По умолчанию обрабатывается $_.
fork
Делает системный вызов fork(2). Возвращает pid (идентификатор
процесса) дочернего процесса родительскому процессу и 0 дочернему процессу.
Значение не определено в случае неуспешного завершения команды. Неуспех может
произойти, например, в случае установки в системе ограничения на количество
процессов данного пользователя. Вот небольшой пример использования этой
функции.
unless ($pid = fork) {
unless (fork) {
exec "what you really wanna do";
die "no exec";
some_perl_code_here;
exit 0;
}
exit 0;
}
waitpid($pid,0);
getc FILEHANDLE
Возвращает следующий символ из файла чтения,
присоединенный к FILEHANDLE или пустую строку в случае конца файла. Если
FILEHANDLE опущен, то считывание происходит из STDIN.
goto LABEL
Эта функция осуществляет переход на точку программы LABEL и
продолжает выполнение программы с этой точки. Точка не может находиться внутри
подпрограммы или foreach цикла, так как в этих случаях требуется предварительная
инициализация.
Использовать в качестве LABEL выражение не рекомендуется, хотя такая возможность
и предоставляется.
grep BLOCK, LIST
grep EXPR, LIST
Обрабатывает BLOCK или EXPR для каждого элемента LIST
и возвращает список элементов для которых значение выражения TRUE. В скалярном
контексте возвращает число элементов для которых EXPR TRUE.
hex EXPR
Возвращает десятичное значение EXPR, интерпретируемого как
шестнадцатеричная строка. По умолчанию обрабатывает переменную $_.
kill LIST
Посылает сигнал списку процессов LIST, первым элементом списка
должен быть номер сигнала. Возвращает число процессов, которым сигнал был
послан успешно. В отличие от shell, если номер сигнала отрицателен, то он посылается
группе процессов.
int EXPR
Возвращает целую часть EXPR, если EXPR опущено, то
обрабатывает переменную $_.
join EXPR,LIST
Соединяет в единую строку строки из LIST. При этом
в качестве разделителей между элементами LIST ставит значение EXPR. Например:
$_ = join( ':',$login,$passwd, $uid,$gid,$gcos,$home,$shell);
keys ASSOC_ARRAY
Возвращает обычный массив, состоящий из ключей
ассоциативного массива ASSOC_ARRAY. В скалярном контексте возвращает число
ключей.
@keys = keys %ENV;
length EXPR
Возвращает длину EXPR в символах. По умолчанию обрабатывает
переменную $_.
link OLDFILE,NEWFILE
Создает файл NEWFILE, присоединенный к файлу
OLDFILE. (В OS UNIX создание нескольких имен для одного файла) Возвращает 1
в случае успеха и 0 иначе.
listen SOCKET, QUEUESIZE
Делает то же самое, что и одноименный системный
вызов. Возвращает TRUE в случае успеха, FALSE иначе.
local EXPR
На самом деле гораздо эффективнее использовать функцию my.
Функция local делает перечисленные переменные локальными в блоке, подпрограмме,
eval или do. Если переменных более, чем одна, то они должны объединяться скобками.
sub RANGEVAL{
local($min,$max,$thunk) = @_;
local $result = '';
local $i;
for ($i = $min; $i < $max; $i++) {
$result = eval $thunk;
}
$result;
}
log EXPR
Возвращает натуральный логарифм EXPR, по умолчанию обрабатывает
переменную $_.
map EXPR,LIST
Подставляет каждый элемент из списка LIST в EXPR (которое
может быть блоком) и возвращает список полученных после обработки величин.
@chars = map(chr, @nums);
mkdir FILENAME,MODE
Создает директорию с именем FILENAME и правами доступа
указанными в переменной MODE. В случае успеха возвращает 1, в противном случае
возвращает 0 и устанавливает значение переменной $!(errno).
my EXPR
Эта функция (так же как и описанная ранее функция local) делает
перечисленные переменные локальными в пределах блока, подпрограммы, eval или do.
Если список состоит более чем из одного элемента, то он должен быть заключен в
скобки. Все элементы в списке должны быть фактическими параметрами. В отличие от local,
переменные локализованные функцией my не видны снаружи блока, подпрограммы или
другой конструкции, внутри которой my употребляется.
next LABEL
Употребляется подобно continue оператору в C - запускает
следующую итерацию цикла.
line: while (<STDIN>) {
next line if /^#/;
...
}
oct EXPR
Возвращает десятичное значение EXPR, интерпретируемого как
строка в восьмеричном формате. (Если строка начинается с 0x, то интерпретируется,
как строка в шестнадцатеричном формате.)
open FILEHANDLE,EXPR
Открывает файл, имя которого описано в переменной
EXPR и привязывает его к FILEHANDLE. Если EXPR опущено, то переменная с таким
же именем как FILEHANDLE содержит имя файла. Если имя файла начинается со знака:
¯<файл открывается на чтение.>файл открывается на запись.>>файл открывается для добавления.|имя файла расценивается как команда, с которой будет организован программный канал, то есть вывод в дескриптор FILEHANDLE будет передаваться на вход программе EXPR.
Если знак | указывается после имени команды, то вывод этой команды
будет ассоциирован с дескриптором FILEHANDLE, из которого будет производиться
чтение. Интересно, что
нельзя открыть двойной программный канал, то есть ассоциировать ввод и вывод
команды с дескриптором файла (что соответствовало бы системному вызову popen в
UNIX).
В случае, когда имя файла оканчивается вертикальной чертой, оно расценивается
как имя команды, вывод которой будет интерпретироваться как ввод из файла
(аналог функции popen(3)).
open(LOG, '>>/usr/spool/news/twitlog');
open DIRHANDLE,EXPR
Открывает директорию с именем EXPR, возвращает TRUE
в случае успеха.
ord EXPR
Возвращает числовое значение в таблице ASCII первого символа EXPR.
По умолчанию обрабатывает переменную $_.
print FILEHANDLE,LIST
Печатает строку или несколько строк, разделенных
запятой. FILEHANDLE может быть именем скалярной переменной, содержащей дескриптор
файла. Если эта переменная опущена то печать идет в выбранный канал вывода.
Если переменная LIST тоже опущена, то печатает переменную $_ в STDOUT.
printf FILEHANDLE, LIST
Эквивалентно print FILEHANDLE, sprintf(LIST).
Первый аргумент LIST интерпретируется как формат печати.
rand EXPR
Возвращает выбранное случайным способом значение между 0 и EXPR.
EXPR должно быть положительным. По умолчанию производит выборку в диапазоне между
0 и 1. (Замечание: если ваша функция постоянно возвращает слишком большие или
слишком малые значения, то скорее всего была допущена ошибка при компиляции
вашей версии Perl. Было установлено неверное значение RANDBITS.)
read FILEHANDLE,SCALAR,LENGTH,OFFSET
Считывает LENGTH байт
данных из FILEHANDLE в переменную SCALAR. Возвращает число считанных байт или неопределенное значение
в случае ошибки. Если вы хотите считать данные не с начала строки,
то для этого нужно установить значение переменной OFFSET.
readlink EXPR
Возвращает значение символьной ссылки, если она существует.
Если же ее нет, то выдает fatal error и устанавливает значение переменной $!.
По умолчанию обрабатывает переменную $_.
redo LABEL
Перезапускает цикл без повторной обработки условия. Блок continue,
если он есть не исполняется. Если LABEL опущена, то команда выполняется для внутреннего
цикла.
line: while(<STDIN>) {
while ($_ ne '\') {
if (ord $_ < 86) {
...
}
redo line;
}
print;
}
ref EXPR
Возвращает TRUE, если EXPR является ссылкой и FALSE в противоположном
случае. Полученное значение зависит от типа объекта на который указывает ссылка.
Существует несколько встроенных типов данных:
package), то в таком
случае возвращается имя пакета.
if (ref($r) eq "HASH") {
print " Это ссылка на ассоциативный массив.\n";
}
if (!ref($r)) {
print " А это не ссылка вовсе! \n";
require EXPR Используется для подключения модулей.
require "oraperl.pm";
reset EXPR
Обычно используется в continue блоке в конце цикла для
переустановки значений переменных. EXPR интерпретируется как список отдельных
символов. Значения переменных и массивов, имена которых начинаются с одного из этих
символов списка переустанавливаются. Например:
¯reset 'X'переустановит все X переменныеreset 'a-z'переустановит все переменные, имена которых состоят из маленьких букв.
rm FILENAME
Удаляет файл или директорию с заданным именем. Возвращает
1 в случае успеха, 0 в противоположном случае и устанавливает значение переменной
$!. По умолчанию обрабатывает аргумент $_.
scalar EXPR
Выражение будет трактоваться в скалярном контексте. Возвращает
значение EXPR.
seek FILEHANDLE, POSITION, WHENCE
Позволяет установить курсор
в файле, определенном в переменной FILEHANDLE, на позицию POSITION в режиме,
указанном в переменной WHENCE. Если переменная WHENCE содержит значение 0, то
позиция отсчитывается от начала файла, если 1 то от текущей позиции и если 2, то
от конца файла. Возвращает 1 в случае успеха и 0 иначе.
select FILEHANDLE
Возвращает текущий выбранный FILEHANDLE. Направляет
вывод в FILEHANDLE.
select RBITS,WBITS,EBITS,TIMEOUT
Вызывает системный вызов select(2) с
определенной аргументами битовой маской.
shift ARRAY
Сдвигает массив ARRAY влево с удалением первого элемента и
возвращает удаленный элемент.
Если в массиве нет элементов, то возвращает неопределенное значение. Если ARRAY
опущен, то обрабатывает массив @ARGV в главной программе и массив @_ в подпрограммах.
sin EXPR
Возвращает синус выражения EXPR (выраженного в радианах). Если
аргумент опущен, то обрабатывается переменная $_.
sleep EXPR
Дает процессу команду остановки на EXPR секунд. Если аргумент
опущен, то процесс зависает навсегда. В таком случае ``сон'' можно прервать, послав ему
сигнал. Возвращает число секунд, в течение которых процесс был в состоянии остановки.
socket SOCKET,DOMAIN,TYPE,PROTOCOL
Создает сокет и привязывает его к
дескриптору файла SOCKET. Остальные параметры описываются так же, как и в одноименном
системном вызове. В начале программы необходимо написать use Socket;.
sort SUBROUTINE,LIST
Сортирует аргументы из LIST и возвращает отсортированный список.
Если список является массивом, то несуществующие элементы массива не учитываются
и не возвращаются. Ниже приведено несколько примеров.
@articles = sort @files;- Лексическая сортировка без использования подпрограммы.
@articles = sort{$a cmp $b} @files;
- То же самое, но с использованием подпрограммы.
@articles = sort{$a <=> $b} @files;
- Численная сортировка по возрастанию.
splice ARRAY,OFFSET,LENGTH,LIST
Удаляет из массива ARRAY элементы,
отмеченные в переменных OFFSET и LENGTH и заменяет их элементами списка LIST,
если таковые имеются. Возвращает удаленные из массива элементы. Длина массива
растет или уменьшается, если это необходимо. Если переменная LENGTH опущена, то
удаляет все, начиная с OFFSET.
split /PATTERN/,EXPR,LIMIT
Разбивает строку на массив строк и возвращает
его. В скалярном контексте возвращает число полученных полей и помещает
полученный массив в @_. Если EXPR опущено то разбивается строка $_. Если PATTERN
тоже опущен, то разбиение происходит по символу пробел. Символы, указанные в
PATTERN, служат разделителями для полей. Разделители могут быть длиннее, чем один
символ. Если переменная LIMIT задана и имеет неотрицательное значение, то разбиение
будет происходить на число полей не более указанного в LIMIT. Если переменная
не определена, то пустые поля отбрасываются, если имеет отрицательное значение,
то это интерпретируется Perl-ом, как отсутствие ограничения на длину возвращаемого
массива. Если шаблону соответствует пустая строка, то EXPR будет разбито на
отдельные символы. Например:
print join(':',split(/ */,'hi there'));
напечатает строку h:i:t:h:e:r:e.
sqrt EXPR
Возвращает корень квадратный из значения EXPR. По умолчанию
обрабатывает переменную $_.
system LIST
Делает то же самое, что и функция exec LIST, за одним исключением:
вместо того, чтобы просто начать выполнять программу , как это делает exec, system
делает fork и порождает еще один процесс, причем родительский процесс ждет завершения
дочернего.
tell FULEHANDLE
Возвращает текущую позицию курсора в файле FILEHANDLE.
Если аргумент опущен, то обрабатывает файл, который читался последним.
tie VARIABLE,PACKAGENAME,LIST
Привязывает переменную к пакету, который будет заносить
значения в эту переменную. Переменная VARIABLE содержит имя переменной, переменная
PACKAGENAME содержит имя пакета. Дополнительные аргументы передаются методу new
этого пакета. Обычно это такие аргументы, которые в дальнейшем могут быть переданы
в качестве параметров dbm_open() функции из C.
tie(%HIST, NDBM_File,'/usr/lib/news/history', 1, 0);
while(($key,$val) = each %HIST) {
print $key, '= ', unpack('L',$val),"\n";
}
untie(%HIST);
Пакет, реализующий ассоциативный массив, должен содержать следующие методы: TIEHASH objectname, LIST DESTROY this FETCH this, key STORE this, key, value DELETE this, key EXISTS this, key FIRSTKEY this NEXTKEY this, lastkeyTIEARRAY objectname, LIST DESTROY this FETCH this, key STORE this, key, value TIESCALAR objectname, LIST DESTROY this FETCH this STORE this, value truncate FILEHANDLE, LENGTH Обрезает файл FILEHANDLE до заданной длины.
undef EXPR
Делает значение EXPR неопределенной величиной, в случае,
когда аргумент опущен ничего не меняет. Не следует пытаться применять эту
функцию к зарезервированным переменным, потому что результат может оказаться
непредсказуемым.
unlink LIST
Удаляет список файлов и возвращает число удачно удаленных
файлов. Если вы не являетесь суперпользователем, то эта функция не может
удалять каталоги. Даже в случае, когда программа запускается с привилегиями
суперпользователя, будьте осторожны, лучше использовать функцию rmdir.
untie VARIABLE Разрывает связь между переменной и пакетом.
unshift ARRAY, LIST
Производит действие противоположное действию функции
shift. Присоединяет LIST к началу массива ARRAY и возвращает новое количество
элементов в массиве.
use Module LIST Осуществляет присоединение модуля к программе.
use strict qw(subs,vars,refs);
values ASSOC_ARRAY
Возвращает обычный массив, состоящий из значений
ассоциативного массива ASSOC_ARRAY. В скалярном контексте возвращает число
элементов полученного массива. Элементы массива могут располагаться в произвольном
порядке.
wantarray
Возвращает TRUE, если контекст исполняющейся подпрограммы
списковый, FALSE в противоположном случае.
write
создает запись (возможно состоящую из нескольких строк) в
соответствующем файле, используя формат ассоциированный с этим файлом. Формат
для текущего канала вывода может быть установлен посредством присваивания
переменной $~{ } имени формата.
Описать и использовать подпрограмму можно несколькими способами:
sub NAME; - подразумевает описание в дальнейшем тела подпрограммы.
sub NAME BLOCK - непосредственное описание.
$subref = sub BLOCK - анонимное описание.
use PACKAGE qw(NAME1, NAME2, NAME3) - включение подпрограмм из модулей.
&NAME(LIST) - скобки обязательны для & формы.
NAME(LIST) - & не обязательно со скобками.
NAME LIST - скобки можно опустить в случае предварительного описания
или включения подпрограммы из модуля.
@_, его элементы
являются ссылками на реальные скалярные параметры. Подпрограмма возвращает
значение, полученное в результате исполнения последнего оператора подпрограммы.
Как уже говорилось, подпрограмма вызывается использованием префикса & перед
ее именем, в Perl 5 этот префикс не обязателен. Пример:
sub MAX {
my $max = pop(@_);
foreach $foo (@_) {
$max = $foo if $max < $foo;
}
$max;
}
...
$bestmark = &MAX(1,2,3,4,5);
Подпрограмма может вызываться рекурсивно. Если подпрограмма вызывается с использованием
& формы, то список аргументов необязателен.
Если вы хотите создать внутри модуля его собственную, невидимую снаружи подпрограмму,
то описание должно быть анонимным:
my $subref = sub {...}
&$subref(1,2,3);
Perl поддерживает механизм альтернативного именного пространства для каждого
отдельного пакета. Обычная программа является пакетом с именем main. Можно
ссылаться на переменные или дескрипторы файлов из других пакетов посредством
использования префикса перед именем переменной, состоящего из имени пакета и
двойного двоеточия: $Package::Variable. Если имя пакета нулевое, то предполагается
использование переменной из main пакета. То есть $::sail эквивалентно
$main::sail. Пакеты могут включать в себя другие пакеты, в таком случае
чтобы обратиться к переменной нужно применить описанное обозначение рекурсивно:
$OUTER::INNER::var.
В пакете могут содержаться только переменные, чьи имена начинаются с буквы или
подчерка, остальные переменные содержатся в пакете main. Кроме того
зарезервированные переменные, как то STDIN, STDOUT, STDERR, ARGV, ARGVOUT, ENV,
INC и SIG также содержатся в главном пакете.
package mypack;
sub main::mysub {
...
}
Таблицы символов пакета хранятся в ассоциативном массиве с тем же именем и
двойным двоеточием в конце. Для пакетов включенных в пакет имя символьной
таблицы составляется аналогичным образом: %OUTER::INNER::.
Существует две функции специального вида - конструкторы и деструкторы. Это
BEGIN и END программы в их описании необязательно использование sub. Подпрограмма
BEGIN исполняется сразу, как только это возможно, то есть в момент, когда
она полностью определена, даже перед тем как обрабатывается остаток содержащего
файла. В файле может быть несколько блоков BEGIN. Они исполняются в порядке
определения.
Подпрограмма END исполняется в самом конце. В файле может содержаться несколько
END блоков, они исполняются в обратном порядке.
В Perl 5 нет специального синтаксиса для описания классов, но пакеты могут
функционировать как классы, если они содержат подпрограммы функционирующие как
методы. Такие пакеты могут также брать некоторые методы из других пакетов-классов.
Для этого необходимо перечислить имена других пакетов в массиве @ISA.
В Perl 5 понятие пакетов расширено в понятие модулей. Модули это пакеты находящиеся в одноименном файле, включенном в библиотеку. Модули подключаются следующим образом:
use Module; или use Module LIST;Это эквивалентно:
BEGIN { require "Module.pm"; import Module; }
Все модули имеют расширение .pm. Если именное пространство модуля пересекается
с именным пространством основной программы то всегда используется use, если не
пересекается то можно использовать require. Понятие объектной ориентации зиждется на трех простых определениях:
В отличие от C++, Perl не имеет специального синтаксиса для описания конструкторов. Конструктор, как уже говорилось раньше, это просто подпрограмма, которая возвращает ссылку ассоциированную с классом (как правило с тем, где определена подпрограмма). Например, типичный конструктор:
package Critter;
sub new { bless {} }
{} создает ссылку на анонимный хэш.
В отличие от C++, Perl не имеет специального синтаксиса для описания
классов. Классом является пакет, чьи подпрограммы выступают в качестве методов.
Для каждого пакета определен специальный массив @ISA, в котором перечислены
пакеты, подключенные к данному пакету. Таким образом в Perl реализован механизм
наследования методов. Метод, принадлежащий другому объекту, подключается как
подпрограмма.
В Perl-е метод имеет синтаксис простой подпрограммы. В качестве первого аргумента
метода выступает объект или пакет. Существует два типа методов: статические и
виртуальные методы.
Статические методы имеют первым аргументом имя класса. Они обеспечивают функциональность
для класса в целом, а не для отдельных объектов принадлежащих классу. Конструкторы
являются, как правило, статическими методами. Многие статические методы просто игнорируют
свой первый аргумент, так как заранее знают, какому пакету они принадлежат.
Другой способ использования статических методов состоит в том, что метод работает
с объектом, используя имя:
sub find {
my ($class, $name) = @_;
$objtable{$name};
}
Виртуальные методы имеют первым аргументом ссылку на объект. Обычно они
помещают
эту ссылку в переменную self или this и в дальнейшем используют ее как обычную
ссылку.
sub display {
my $self = shift;
my @keys = @_ ? @_ : sort keys %$self;
foreach $key (@keys) {
print "\t$key => $self ->{$key}\n";
}
}
Существует два способа обратиться к методу. Во-первых, можно вызвать его просто как подпрограмму. Но в таком случае не работает механизм наследования. Второй способ лучше просто проиллюстрировать примерами.
$fred = find Critter "Fred"; display $fred, 'Height', 'Weight';Это можно записать так:
display {find Critter "Fred"} 'Height', 'Weight';
Когда удаляется последняя ссылка на объект, этот объект автоматически удаляется.
Это может произойти даже после завершения программы, если ссылки на объект
содержались в глобальных переменных. Если необходимо контролировать процесс
удаления объекта, можно определить в объекте специальный метод, называемый
деструктором. Деструктор объекта (в отличие от C++) имеет
фиксированное имя DESTROY и вызывается перед удалением объекта. В нем можно
реализовать дополнительные процедуры, необходимые для корректного
завершения (например, удаление временных файлов, используемых объектом).
БД "Телефонный справочник НГУ" была создана в СУБД "Paradox4.5" и состоит из трех таблиц:SPIS.DB, STR.DB, PODR.DB.
STR.DB - структурные подразделения НГУ (справочник)
| Подразделение | Название подразделения |
PODR.DB - подразделения НГУ "нижнего уровня" (справочник)
| Подр | Название подразделения |
SPIS.DB - Список телефонных номеров
| Подразделение | Название подразделения "1-го уровня" |
| Подр | Название подразделения "2-го уровня" |
| Должность | Название должности |
| Звание | Научное звание |
| ФИО | Фамилия имя отчество |
| Сл# телефон | Служебный телефон |
| Дом# телефон | Домашний телефон |
| Место | Физическое месторасположение телефона |
В пользовательском интерфейсе базы данных предусмотрены следующие возможности:
Ввиду крайне слабой нормализации базы данных и того, что справочные таблицы использовались лишь для копирования информации, все данные оказались сосредоточены в одной таблице - SPIS.DB.
Для организации WWW - интерфейса к БД был использован пакет WOW [См. Главу 7. "Использование пакета WOW"], обеспечивающий взаимодействие WWW - сервера с SQL - сервером фирмы Oracle.
Перенос таблицы SPIS.DB базу данных Oracle был осуществлен с помощью пакета Microsoft Query, используя технологию ODBC. Был создан запрос на все поля таблицы ( select * from SPIS.DB), и результат его выполнения был сохранен ("Файл/Сохранить как") в базу данных Oracle как таблица с именем TEL_SPIS с сохранением имен для всех полей.
Непосредственно сам интерфейс взаимодействия с БД "Телефонный справочник НГУ" реализован на языке PL/SQL в виде пакета процедур, хранимых в базе данных Oracle. В этом интерфейсе реализованы следующие возможности (см. рисунок П3-1):